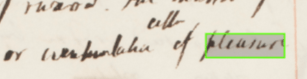Close
Close

UCL–University of Toronto: Transkribus, HTR, and medieval Latin abbreviations
By Chris Riley, on 20 April 2021
Following the successful receipt of funding under the University College London–University of Toronto Call for Joint Research Projects and Exchange Activities in 2019, a team composed of Professor Philip Schofield (UCL), Professor Michael Gervers (Toronto), Dr Chris Riley (UCL), Hannah Lloyd (Toronto), and Dr Ariella Elema (Toronto) sought to address two questions surrounding Transkribus, Handwritten Text Recognition (HTR), and abbreviated words within medieval Latin manuscripts:
1.) Could Transkribus be trained consistently to process abbreviated Latin words, which can represent up to half the vocabulary of medieval legal texts, and hence feature in a substantial proportion of the Documents of Early England Data Set (DEEDS) corpus at the University of Toronto?
2.) Could Transkribus be made consistently to recognise hyphenated words which span multiple lines of text (insofar as they are both in Latin and abbreviated)?
![]()
Prior to the commencement of the project, attempts to generate HTR models within Transkribus in the hope that they would be able to process material within the DEEDS corpus were unsuccessful and yielded very high Character Error Rates (CERs) and Word Error Rates (WERs)—percentages which reflect the ability of the software programme to interpret individual characters and individual words within untranscribed pages respectively. As shown in Figure 1 below, the WERs for these models, which were generated prior to the award of funding, reached as high as 94.2%, or 54% on average, and the CERs reached as high as 49.6%, or 25.91% on average, making them far from ideal for research purposes, and certainly warranting further efforts in the hope of bringing them down significantly. Figure 1 below shows the model results achieved prior to the beginning of the project.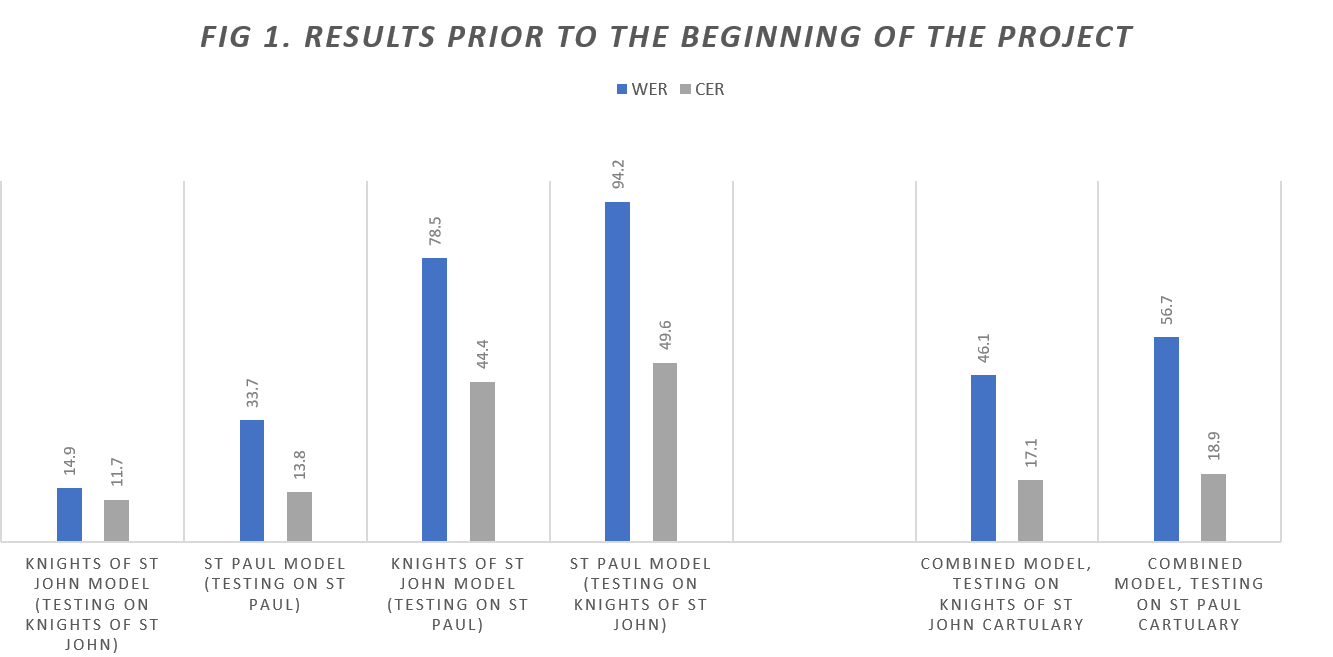
Our goal was therefore to bring down these WERs and CERs, preferably to below 10%, in order to make the use of HTR a viable alternative to the often costly use of standard human transcription by an individual or group of individuals with the relevant Latin and palaeographical skills. The initial dataset which was used to this end was composed of 272 pages with their corresponding transcripts from the DEEDS database, representing 10,000 lines of text in total.

The first step was to go through the existing subcollections from the DEEDS corpus on Transkribus in order to improve all of the text regions and baselines which the software had added to the manuscripts. This was to ensure that all text was included in the text regions, and all baselines covered every part of each word on each line, as errors here may have caused significant reductions in the WERs and CERs shown in Figure 1. Once this was completed, the transcripts were checked against the images in order to ensure that they were as faithful as possible to the manuscripts before proceeding with the creation of improved HTR models.
On 6–7 February 2020, prior to the creation of several new HTR models based upon this improved groundtruth (that is an accurate transcription and representation of a set of manuscripts), Riley and Lloyd attended the Transkribus User Conference in Innsbruck, Austria, where they delivered a presentation to around 100–150 attendees on the project and the methodology that would be used. This experience, and the advice they received from other attendees, was invaluable in informing their research during the ensuing phases of the project, not least with regard to how they would approach the issue of processing such a large number of Latin abbreviations.
After the Transkribus User Conference, Lloyd visited the Bentham Project at UCL for a period of two weeks. This time was spent refining their existing groundtruth, creating and testing three new HTR models (see below, including Figure 2), building a large dictionary of abbreviations, and testing the first instalment of the ‘abbrevSolver-master’ Python script, developed by Ismail Prada, an independent programmer from Zurich, Switzerland.
After receiving valuable advice regarding how best to address our principal aim of processing Latin abbreviations and after making contact with Prada and experimenting with his script, we created the abbreviation dictionary, consisting of over a hundred abbreviated Latin words, both in their expanded and contracted forms, in which the latter were represented by compatible special characters that best reflected how they appeared in type. These abbreviations were also categorised as prefixes, suffixes, or standalone abbreviations, which would alter how they would be processed by the algorithm.
As the script was new and untested, this process, and the creation of an abbreviation dictionary and special character set with which it was compatible, was especially problematic, with multiple versions of the appropriate tab-separated Excel file containing the abbreviated words and several varieties of special characters being created in an attempt to get it to function as intended.
After a frustrating amount of trial and error, it was decided to proceed with the finding-and-replacing of the abbreviated words without the use of the script. Around a third to a half of the shortened word forms in the abbreviation dictionary were manually replaced, with each word replaced wherever they appeared in each folio and then tagged accordingly. This process was extremely time-consuming, mainly owing to the search function within Transkribus being slightly awkward when navigating large pages of results.
The original script, with which we had a substantial number of problems (attributable to our use of Windows 10 rather than Linux, and Excel rather than Microsoft Visual Studio Code, our choice of certain special characters which turned out to be incompatible, and a period when we were unable to elicit any support from the developer), was also far from perfect in how it would have operated had it worked correctly. One had to run it for each and every .xml file saved through Transkribus and copy and paste the data back and forth for each manuscript image. Given that manually finding and replacing abbreviated words through Transkribus and tagging them accordingly was prohibitively time intensive, it was enormously helpful that, after resuming contact with Prada, he not only fixed the first version of the script and provided feedback on the form of our abbreviation dictionary, but developed a superior API equivalent that permitted processing the transcripts in bulk.
With the newer API script, everything is done by connecting directly to Transkribus, after giving it the collection editor’s username and password and the collection ID (with the format of the abbreviation dictionary remaining the same as the earlier iteration). As well as being quicker, the new script is simpler to use. After running a basic command, the script communicates with Transkribus and uses its find-and-replace algorithm on each subcollection, replacing each term it finds from the abbreviation dictionary with its shorter equivalent and tagging them as abbreviated. Once the API version of the abbrevSolver script had been run, over one hundred abbreviations from our dictionary were incorporated into the transcripts for the existing 272 images almost immediately, before an impressive new model was created, our fifth in total.
Five new HTR models were generated at this stage of the project, using our available dataset as it progressed, with the fourth and fifth having been generated after using the new version of abbrevSolver-master, and with a sixth and seventh being created at a later juncture. These initial five models and their individual statistics are shown in Figure 2 below.
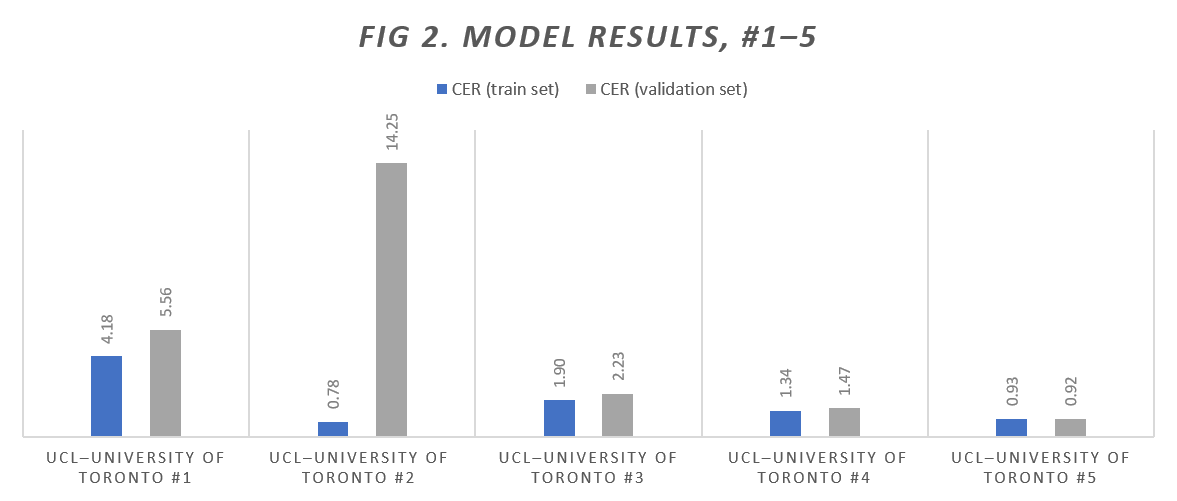
With the exception of the second model, which provided a very good CER but anomalously high WER, we have seen an extremely promising decline in both CERs and WERs over the course of the project. In the fifth in particular, we developed a model that, at least on paper, outperformed many of those that were then publicly available on Transkribus for similar types of material, in terms of their CERs on their train and validation sets.
When compared to the models that were generated prior to the commencement of the project, the two models that were generated after using the new script are extremely good. Specifically, UCL–University of Toronto #5, yielded CERs 13.7% lower and WERs 37.15% lower than those achieved before the project began, and far below the ideal threshold of 10%.
Two batches of material were uploaded onto Transkribus after the creation of our fifth model for testing purposes—namely BL Add. MS 46,487 and Egerton MS 3,031—consisting of 300 images in total. The biggest problem with these two collections was the quality of the images, with their dimensions being too low to work effectively with Transkribus. Soon afterwards, however, we were able to obtain two much more promising batches of material—namely Anglo-American Legal Tradition (AALT) material and material from two cartularies held by Christ Church College, Oxford.
The first round of AALT testing was performed on images and transcripts from CP/25/1/88, held by the National Archives in the UK. For these, we achieved an average CER of 24% and average WER of 50%, which were disappointing compared to the model statistics given above—even though, with three or four of the worst-performing folios excluded, the average CER dropped to 21.58% and the average WER dropped to 48.15%. Our best-performing folio from CP/25/1/88 achieved a CER of 8.82% and a WER of 28.57%, and another achieved a CER of 9.13% and a WER of 27.78%.
A further problem with this material, alongside the one of image quality, was the brevity of each transcript. While they did include several abbreviations, the transcripts themselves only consisted of between two and five lines of text and did not cover whole pages. This made the process of testing much less time-consuming because the groundtruth could be created very quickly, but the standardised form that each folio took, and the inclusion of a large number of words common to each folio, meant that our error rates may have been misleadingly high in some instances where the models performed relatively well.
We were thereafter able to obtain ten further, complete and thus lengthier AALT transcripts. Having uploaded the lengthier AALT transcripts, the latest model was run again and achieved a much better CER of 15.62% and a static WER of 46.78%. There were only a few folios where the results of the shorter transcripts were better than the longer ones, which is very positive, given that the greater number of words left a far greater margin for error.
For comparative purposes, two third party models were then run, namely Charter Scripts XIII–XV and HIMANIS Chancery M1+, with the aim of comparing their results with those from our own models. For 50% of the folios, Charter Scripts XIII–XV out-performed our model, suggesting that the material on which it is based is more akin to the content of AALT than to the material used to generate UCL–UoT #4–5. On average, though, the increase was negligible—namely a 0.35% difference in the CER and a 2.26% difference in the WER. (The standard HIMANIS model was worse than ours in both respects).
Overall, these results were not as promising as those from the material which was used to generate our own models. Compared to the AALT results, our fourth model gave a 14.44% better CER and a 41.93% better WER, which are enormous differences when it comes to the practicability of using Transkribus as an alternative to human transcription. This indicated a significant dissimilarity between the AALT material and our own and would require a much expanded groundtruth in order to see an improvement, something that we went on to do with the Christ Church material discussed below, namely the Cartulary of Eynsham Abbey and the Cartulary of St Fridewide’s Priory.
Approximately 300 images were downloaded for Eynsham and around 180 for St Frideswide, with the available transcripts separated by line and matched to the folios on Transkribus. As with the BL Add MS 46,487 and Egerton MS 3,031 material, however, the image quality was very poor and this was fully reflected in the testing results. This round of testing provided poor WERs of around 82.02% and CERs of around 32.15%, double those from the second round of AALT testing.
After this, Christ Church College was contacted directly. After explaining the nature of our project, and inquiring about obtaining some better quality variants, they very kindly waived their £10 per .tiff file fee and sent a small number of images on which we could perform some testing. These higher-resolution images made a huge difference; our CER improved by 14.42% and our WER by 36.3%.
These images were also tried with the two third-party models mentioned above, Charter Scripts XIII–XV and HIMANIS Chancery M1+, which achieved lower WERs of 39.83% and CERs of 15.21%. For one folio, Generic Charters out-performed our model by 3.19% CER and 5.38% WER. As with the AALT testing attempt, this suggests a dissimilarity between our material, the testing material, and the material used by that model’s creators, thus indicating that the cartulary data should be integrated into our groundtruth and that a new model ought to be created.
During the cartulary testing, several different dictionary settings within Transkribus were experimented with when running each model, with the ‘Language model from training data’ option providing by far the best results. This suggests that we are in fact getting significant added value from our abbreviation dictionary, even above what is possible through using a very extensive third-party Latin dictionary repository composed of around 100,000 words.
The most substantial problem with these cartularies, however, was that only a handful of the images that were sent from Christ Church had their corresponding transcripts included in the DEEDS corpus. Because of this, only two out of the batch of high-resolution images could be tested, both of which being from Eynsham, so the testing results were relatively positive but not ideal.
Christ Church then kindly agreed to provide us with all of the high-resolution files for both the Eynsham and St Frideswide cartularies for which we possessed transcripts (approximately 125 in total). The issue we faced, however, was with our available transcripts of the Eynsham and St Frideswide material, which had to be checked closely against the manuscripts for accuracy before Text2Image matching could take place. In the process of doing so, we uncovered some serious textual issues, for instance some lines in St Frideswide had been transcribed with one letter representing each word with spaces in between, thus making it almost unusable for the purpose of expanding our groundtruth, at least without a more expert eye to correct the Latin.
Elema then checked the text thoroughly. The working transcripts were based on editions of the Eynsham and St Frideswide cartularies published in 1907 and 1895 respectively. Elema corrected the text to reflect more closely what was written in the manuscripts. Where the editors had standardized the Latin orthography and capitalisation, Elema returned the words to their idiosyncratic medieval forms, and where the editions had replaced redundant phrases with ellipses, she filled in the complete text. Since the model was already capable of resolving common symbols and abbreviations, she transcribed short abbreviations, like the symbols for est, et, con, per, and quod in their expanded form. Less common abbreviations and ones that left out more than two or three letters in a row were transcribed as they appeared in the manuscript and noted in a spreadsheet so that they could be tagged later and added to the model’s dictionary of abbreviated words.
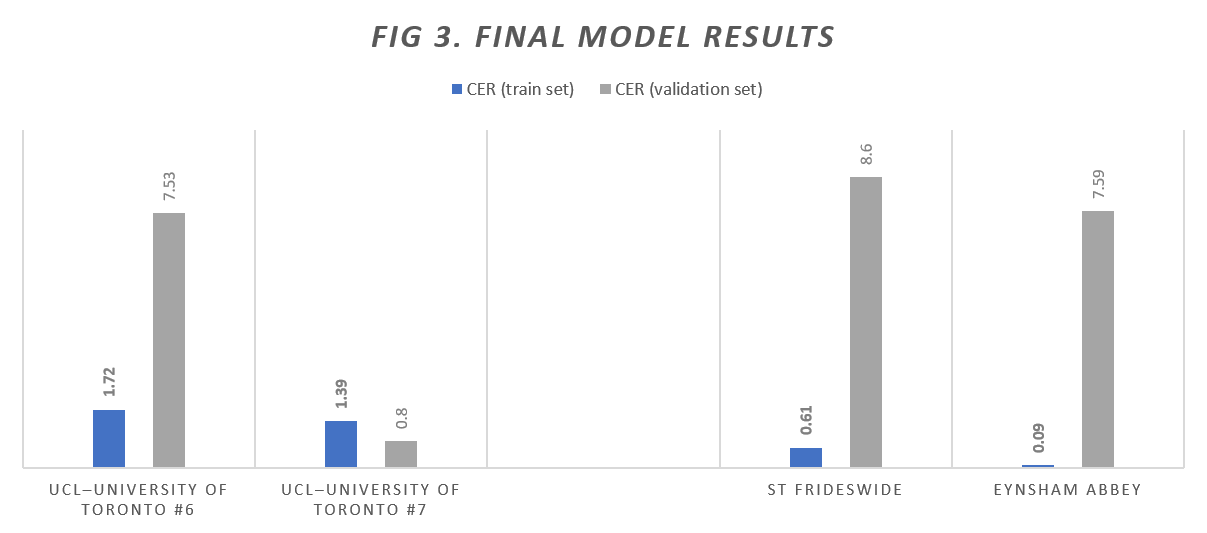
The combined sixth model, entitled UCL-University of Toronto #6—created using 150,488 words and 10,519 lines of text in total—achieved an impressive CER on the train set of 1.72%, but owing to an issue which arose when allocating the validation set, the CER on the validation set was very high, namely 7.56%. Because of this anomalously high CER on the validation set, a seventh and final model was created, entitled UCL-University of Toronto #7. This was based upon 140,158 words and 9,780 lines of text, and returned an impressive CER on the train set of 1.39% and a CER on the validation set of 0.80%, which we were very happy with overall.
After these two models had been created, we conducted some testing, both on the two cartularies from Oxford with which we had expanded our original groundtruth, and on the original collections on Transkribus. On the former, the Oxford material, the results were good: on St Frideswide we achieved a CER on the train set of 6.28% and a CER on the validation set of 7.45%; and on Eynsham we achieved a CER of 5.89% on the train set and a CER of 13.68% on the validation set—not perfect, particularly the validation CER for the Eynsham cartulary, but far better than what we had achieved before obtaining high-quality images and correcting our transcripts.
These figures from the Oxford cartulary testing, however, were not quite as promising when compared to some of those achieved when creating discrete, smaller models, unique to each cartulary, without borrowing elements from the collections we had used to generate our first five models. For the discrete St Frideswide model, developed from a modest 14,781 words and 1,113 lines of text, the CERs were 1.93% better than those achieved when applying UCL–University of Toronto #7 to the same material, but the WERs were a negligible 0.03% worse. For the discrete Eynsham model, developed from 6,074 words and 825 lines of text, the CERs were 2.97% better than those achieved when applying UCL–University of Toronto #7 to the same material, and the WERS were a good 7.56% better. Figure 3 below shows the results of models six and seven, as well as the results of the two models based on the Oxford cartularies which were used for comparative purposes.
Most importantly, though, the expansion of our groundtruth with material from Oxford and the creation of our seventh model, did improve our testing results on material from the DEEDS corpus when compared to anything we had been able to achieve by using the first five models, which were created exclusively with DEEDS manuscripts, giving final figures for testing on average across all our collections of a CER of 0.53% and a WER of 1.09%, with some individuals subcollections on Transkribus achieving CERs as low as 0.13%, and some achieving WERs as low as 0.13% also. Figure 4 below shows the average testing results of our seventh model when applied to material from the DEEDS corpus and to St Frideswide and Eynsham, as well as the testing results of the small St Frideswide- and Eynsham-specific smaller comparative models.

In order to showcase the final model and to exhibit to others the nature and scope of the project, on 3 March we hosted a successful virtual launch event, chaired by Schofield and featuring short talks by Gervers, Causer, Lloyd, Riley, and Elema. During the session, Schofield introduced the project and its funders, and provided biographies of each of its speakers, after which Gervers discussed the history of the DEEDS project from its inception in the 1970s, the approximately 60,000 charters of which it is comprised, topic modelling, and the dating of the material. Causer then discussed the Bentham Project, Transcribe Bentham, and the Project’s involvement in the READ programme and the development of Transkribus, before Lloyd discussed the early endeavours to apply HTR technology to material from the DEEDS corpus. Lloyd then handed over to Riley, who proceeded to discuss the preliminary model creation attempts and the results of the first four UCL–University of Toronto models, the use of abbrevSolver-master and its API variant, followed by an analysis of the sixth and seventh models and their testing results on material from the DEEDS corpus and the Oxford cartularies respectively. Between Riley’s discussion of models one to four and models six to seven, Elema discussed her methodology and the challenges she faced and overcame when correcting the groundtruth of the Oxford cartularies. Finally, the speakers answered questions from those in the audience.
The following week, on 10 March, Riley delivered a training workshop, teaching new and intermediate users how to use the Transkribus software platform. After a recap of the previous week’s event, the session covered account creation, installation and setup, Transkribus credits and how many are required to process certain quantities of pages, creating collections and importing manuscript images, applying baselines and text regions, adding transcripts, applying tags, creating and applying HTR+ models (including UCL–UoT #7), analysing results and comparing one’s groundtruth against one’s HTR-generated transcripts, searching and keyword-spotting, and exporting the resulting data.
The total number of attendees across both sessions was approximately 267, and the videos of both events are now available to view on the Bentham Project’s ‘Bentham Seminar’ channel on YouTube.
Our final model and its training data are now publicly available through Transkribus, further information on which may be found here. If you do use it, we would love to hear about your results via email.
We would like to express our sincere gratitude to everyone who has been involved in the project, as well as to our funders and to those who supplied manuscript images, and to everyone who attended the model launch event on 3 March or the workshop on 10 March.
Chris Riley, Bentham Project, Faculty of Laws, UCL
6 May 2020