Close
Close

Surveying Generalisation in Reinforcement Learning
By Sharon C Betts, on 19 January 2022
By Robert Kirk, PhD Candidate
Reinforcement Learning (RL) could be used in a range of applications such as autonomous vehicles and robotics, but to fulfil this potential we need RL algorithms that can be used in the real world. Reality is varied, non-stationarity and open-ended, and to handle this algorithms need to be robust to variation in their environments, and be able to transfer and adapt to unseen (but similar) environments during their deployment. Generalisation in RL is all about creating methods that can tackle these difficulties, challenging a common assumption in previous RL research that the training and testing environments are identical.
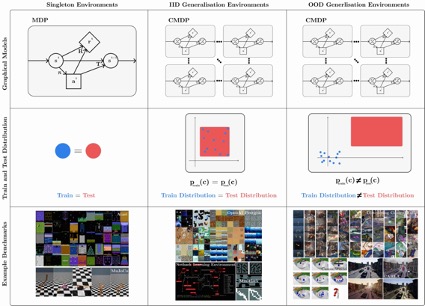
However, reading RL generalisation research can be challenging, as there is confusion about the exact problem being tackled and the use of terminology. This is because generalisation refers to a class of problems within RL, rather than a specific problem. Claiming to improve “generalisation” without being more specific about the type of generalisation that is being improved is underspecified. In fact, it seems unlikely we could improve all types of generalisation with a single method, as an analogy of the No Free Lunch theorem may apply.
To address this confusion, we’ve written a survey and critical review of the field of generalisation in RL. We formally describe the class of generalisation problems and use this formalism to discuss benchmarks for generalisation as well as methods. Given the field is so young, there’s also a lot of future directions to explore, and we highlight ones we think are important.
To find out more, check out the extended blogpost here!