 Close
Close

Finding Women in the Sloane Lab Knowledge Base
By Lucy Stagg, on 7 November 2024

A Guide to Finding Women in the Sloane Lab Knowledge Base, available to download here
The Sloane Lab is pleased to announce the release of three new resources — an online exhibition, dataset, and research guide — developed by Dr Rosalind White, Sloane Lab Community Research Fellow at University College London, as part of her project In the Margins of Early Modern Science: Pioneering Women in Sloane’s ‘Paper Museum’.
These resources leverage the rich repository of data provided by the Sloane Lab Knowledge Base to explore the contributions of women within Sloane’s “Paper Museum” — a vast compendium comprising over 1,000 illustrated books, 100 picture albums, an estimated 60,000 drawings, prints, and paintings, as well as manuscript catalogues spanning thousands of handwritten pages.
Together, they showcase how the SLKB can serve as a dynamic resource for critical inquiry.
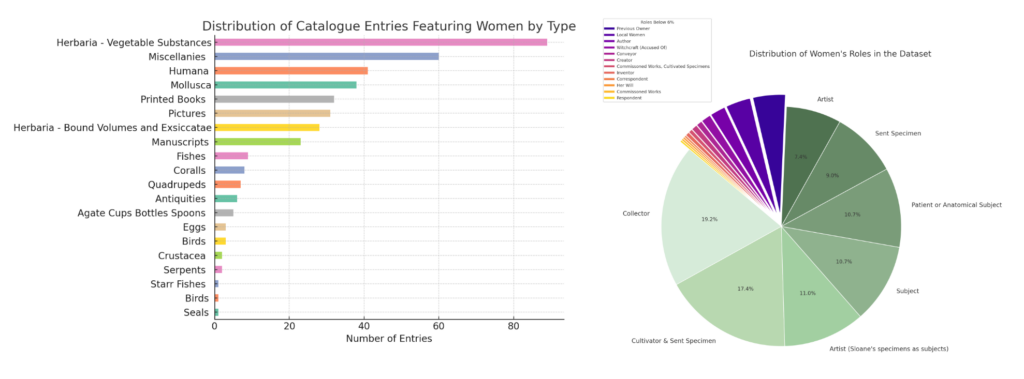
The dataset establishes a foundation for enhancing the representation of women within Hans Sloane’s collections through the Sloane Lab Knowledge Base. It offers a snapshot of the various ways women are documented and represented in the collections detailing their roles (e.g., artist, author), the type of entries associated with them (e.g., Pictures Catalogue Entry, Printed Books Catalogue Entry), as well as additional information about their work or the context of their contributions. Where possible, a link has been provided to each entry in the SLKB, allowing for deeper exploration. The dataset can be downloaded as Excel file (.xlsx) or in CSV format.
A Guide to Finding Women in the Sloane Lab Knowledge Base offers a practical starting point for researchers seeking to uncover the hidden narratives of women in Sloane’s collections. It outlines the methodological approach used to identify women’s contributions, highlighting how often these roles are obscured by gaps in the original cataloguing efforts, where names and direct references to women’s involvement are frequently absent. The guide is part of a broader effort to enhance how narratives of marginalised individuals are accessed, understood, and valued within the SLKB. The guide can be downloaded as a PDF file in both double-page and single-page view.

The online exhibition, In the Margins of Early Modern Science: Pioneering Women in Sloane’s ‘Paper Museum’, invites users to explore the untold stories of the women who shaped Sir Hans Sloane’s vast collections. Research cases studies are brought to life through a variety of interactive exhibits.
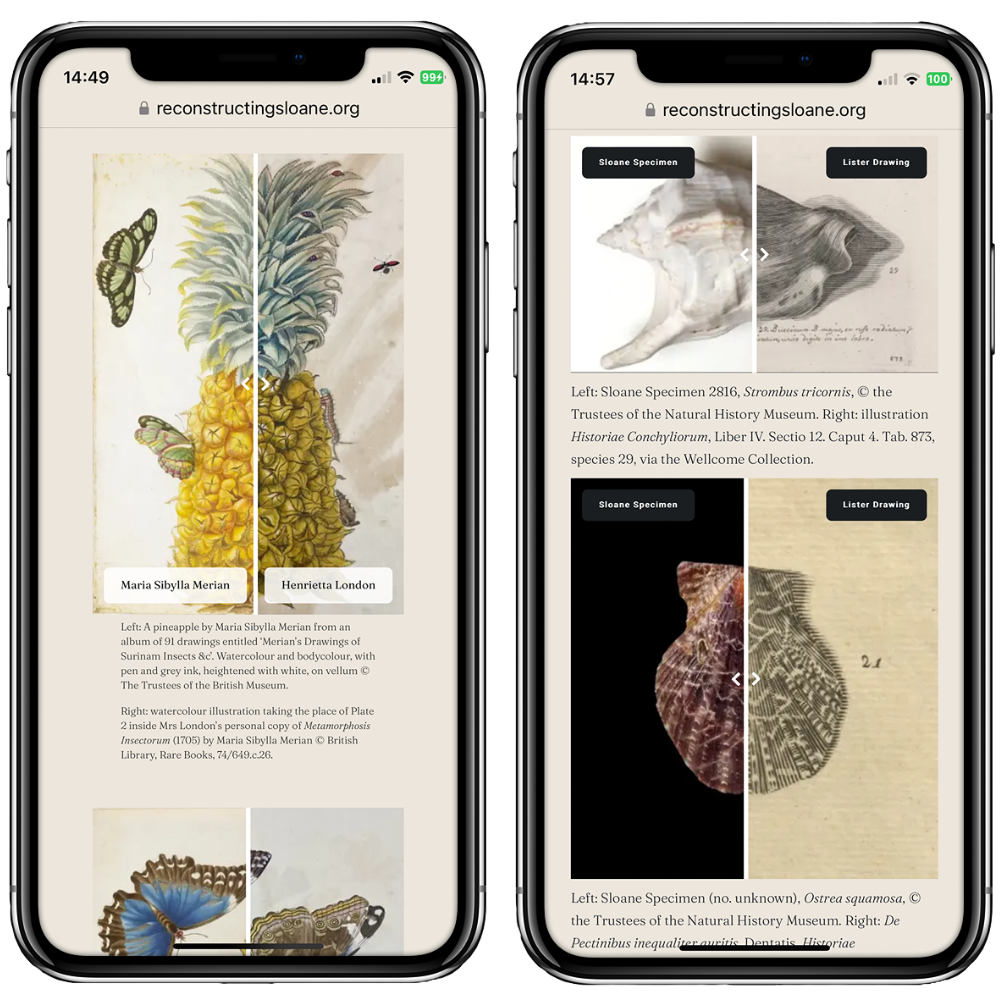
The exhibition spotlights the work of Elizabeth Blackwell, author and artist of A Curious Herbal; horticultural virtuoso Mary Somerset, the Duchess of Beaufort; and illustrators Anna and Susannah Lister, daughters of conchologist Martin Lister. It also highlights contributions from lesser-known women, such as botanical artists Ellen and Margery Power, and the mysterious ‘Mrs. London,’ whose watercolour illustrations appear in her personal copy of Maria Sibylla Merian’s Insects of Surinam.
Collectively, these resources empower users to explore the Sloane Lab Knowledge Base in innovative ways, demonstrating the impact that digital tools and critical methodologies can have in uncovering the contributions of individuals relegated to the margins of early modern science.
If you would like to follow along with Rosalind’s future research projects, you can find her on X (formerly Twitter) @DrRosalindWhite.


")

