Close
Close

How to predict travel chaos
By Oli Usher, on 1 June 2015
It’s a scenario London commuters are all too familiar with: a muffled announcement, ‘signal failure’ or ‘passenger action’; a station closed and thousands of passengers’ journeys interrupted.

London’s transport network is extensive, but fragile.
Everyday disruptions to the service have knock-on effects across the system.
Some are easy to predict – a closure at Mornington Crescent will mean more people exiting at Camden Town, on the same line and only a few minutes’ walk away.

Mornington Crescent: quiet, only on one line, and located near to another station. Photo: Diamond Geezer (CC-BY-NC-ND)
Others are far more complex – how would a closure at a busy hub like Euston affect traffic across the network?
Two innovations of the past few decades mean that travel chaos is far more predictable than it was. One is the wealth of data captured by the Oyster Card system, which has been recording passengers touching in and out of the Underground since 2003. The other is the advance in computing power which makes statistical analysis of millions of journeys easy.

Ricardo Silva
One statistician who has looked at Oyster data to chart the impacts of disruption on the underground is UCL’s Ricardo Silva. He has recently built a statistical model that predicts the knock-on effects of unplanned station and track closures across London’s urban rail network.
His work could help transport operators react more effectively to disruption. It can potentially be used to identify where bus services need to be beefed up, as well as identify bad decisions passengers make when reacting to disruption, which can help station staff make more useful announcements about alternative routes.
At the heart of Silva’s model is a database of every journey taken on the Tube, Overground and DLR using Oyster Cards, over 70 randomly chosen weekdays in 2012 and 2013 – covering tens of millions of passenger journeys.

The Oyster Card system is used for over a billion journeys per year on the Tube alone – generating a wealth of data in the process. Photo © TfL Press Office, all rights reserved
Transport for London (TfL) strip out all personal information, such as the passenger’s name or Oyster Card serial number before supplying the data, and give each passenger a randomly allocated ID number. This means that Silva can track individual journeys across the network – including which stations the passengers travel between, and at what time – without invading their privacy.
Alongside the passenger data, he has TfL’s log of all incidents on those days, so he can tease out the difference between passenger behaviour when the network is running smoothly, and when it is being disrupted by a partial closure.
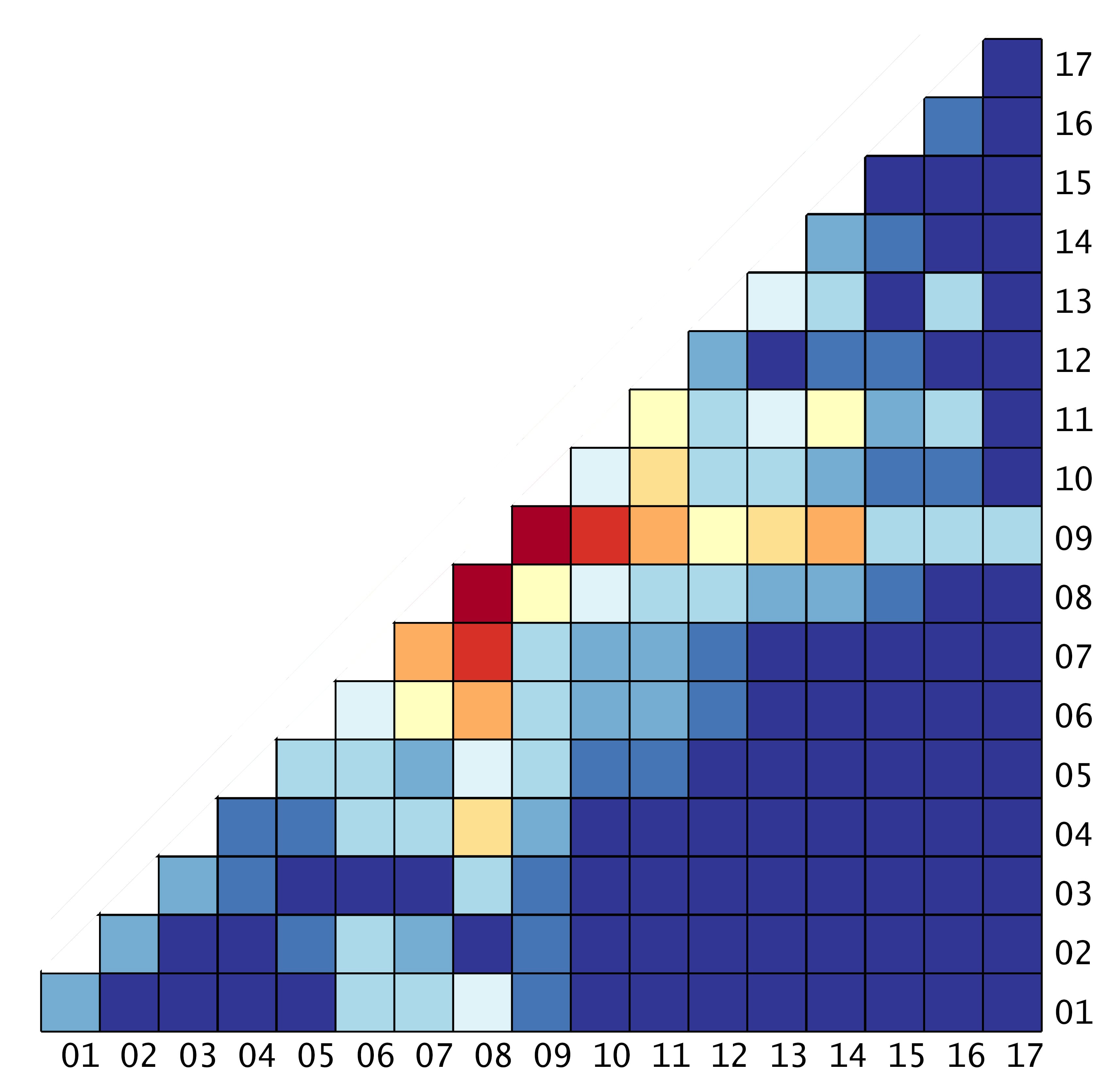
London’s urban rail network has 374 stations, which means there are almost 140,000 possible paths a passenger can take as they navigate their way across the capital. (There are a handful of pairs of stations, Silva says, that nobody travelled between in any of the 70 days he studied.)
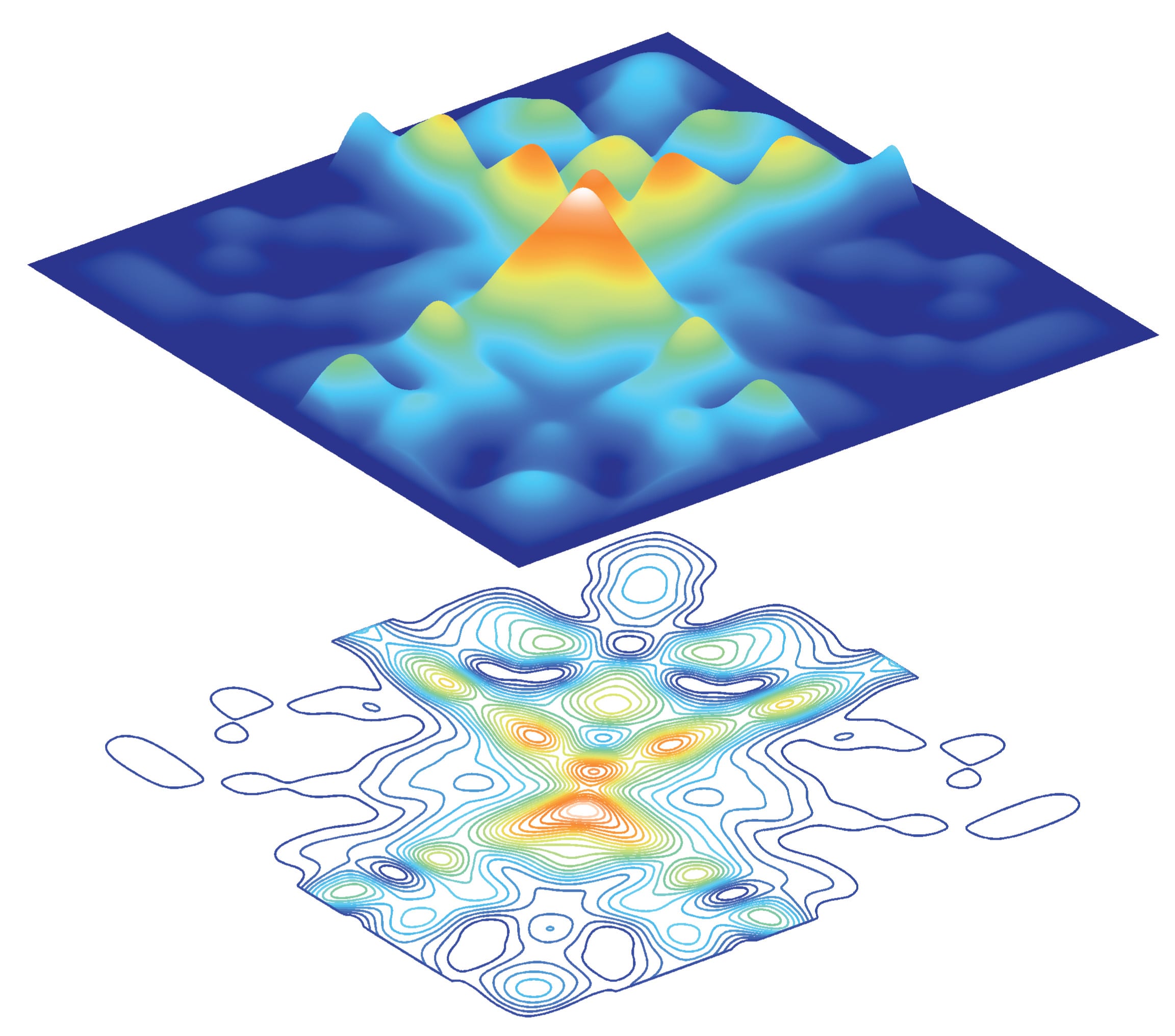
Silva’s model predicts minute by minute how many journeys are being made between each pair of stations, how many passengers will enter and leave the system at each station, and how many will be inside the system at any given time.
In its most basic form, the model is simply a description of where passengers are entering and leaving the system at any given time; a reflection of how the network is when it’s working normally. But unlike the real network, he can experiment, closing stations or lines and seeing how the virtual passengers adapt to the disruption.
In principle, the model can give staff immediate feedback about what passengers are likely to be doing at that point, when an unplanned service disruption takes place. However, implementing real time feedback will require further work as the existing technical facilities are not ready for that yet.
Silva’s model takes a lot of computing power – it takes a few days to run a simulation on an ordinary desktop computer – but it is not unmanageable. Extending the model to take account of passenger flows through the transport network, or to run the simulation quicker would require supercomputer facilities such as UCL’s Legion Cluster.

UCL’s Legion Cluster supercomputing facility. Photo: Tony Slade, © UCL Creative Media Services (all rights reserved)
The model doesn’t only apply to London – it is applicable to any transport network where passengers’ entry and exit points are tracked, meaning it could be useful for transport authorities around the world.