 Close
Close

Health indicator recording in UK primary care electronic health records: key implications for handling missing data
By Nathan Davies, on 13 March 2019
In this post Tra My Pham talks about their latest paper which has investigated the recording of data in UK primary care electronic health records and the implications this has on conducting research using these records.
GP electronic health records provide a large amount of information and data for medical research. These information source help us to study individuals’ health over time, and offer many opportunities for research into populations that would otherwise be difficult and/or expensive to undertake.
Large UK primary care databases (GP electronic health records) capture information on key health indicators such as height, body weight, blood pressure, cholesterol level, smoking status, and alcohol consumption. These are relevant risk factors for many health conditions including diabetes and heart diseases, which remain leading causes of the global disease burdens. In primary care when patients register with their GP practices, it is typical that their past and current medical history is documented. Most individuals will have a record of the above health indicators as part of their registration. Thereafter, this information is mainly recorded if it is directly relevant to the patients’ care, ie, some patients will have several records over time while other will only have a few. Therefore, data can often be incomplete, which poses a challenge for their use in research. In this study, we aimed to further understand how common health indicators are recorded in the UK primary care setting, and whether there are potential implications for dealing with incomplete data in medical research.
We analysed records of height, body weight, blood pressure, cholesterol level, smoking status, and alcohol consumption from 6.3 million individuals aged 18–99 in The Health Improvement Network (THIN) database during the period 2000–2015. There were differences in the recording of these health indicators by sex, age, time since registration with the GP practices, and disease status. In particular, women aged 18–65 years were more likely than men of the same age to have these health indicators recorded, and this gap narrowed after age 65 (Figure 1). More than 60% of individuals had their health indicator data recorded during the first year following registration with their GP practices. After that, this proportion fell to only 10–40%. The recording of relevant health indicators were more regular among individuals with chronic diseases compared to those without, eg, body weight being measured more frequently for diabetes weight management (Figure 2).
Health indicator recording in general practices followed, to some extent, the GP consultation patterns by age and sex. In particular, younger women were more likely to see their GPs than younger men. Therefore, it seemed likely that for women, many weight and blood pressure measurements may have been taken in conjunction with their consultations for contraception and pregnancy. Our results suggested that many practices offered general health checks for their newly registered patients, during which patients’ health indicators were recorded. A GP incentive scheme was introduced in 2004, under which GPs receive financial payments based on quality targets and they have to record data, eg, health measurements, in order to meet these targets. Since this scheme began, many individuals with chronic conditions have had their health indicator measurements recorded on a more regular basis, which was reflected in our findings.
For health research studies using primary care databases, incomplete information on common health indicators will affect statistical analysis. In particular, analyses based on the available information alone may be misleading. It is standard in medical research to overcome the problem of incomplete data by using a statistical method called multiple imputation. The method involves using the data collected to estimate the unseen data (several times for each unseen value), so that analysis can proceed as though complete data had been collected. Based on the findings of our study, multiple imputation taking into account the differences in health indicator recording by individuals’ demographic characteristics and disease status is recommended, but should be considered and implemented carefully.
Our article and relevant references can be found at:
Petersen I, Welch CA, Nazareth I, Walters K, Marston L, Morris RW, Carpenter JR, Morris TP, Pham TM (2019). Health indicator recording in UK primary care electronic health records: key implications for handling missing data. Clinical Epidemiology, 2019 (11) pp. 157-167. https://doi.org/10.2147/CLEP.S191437.
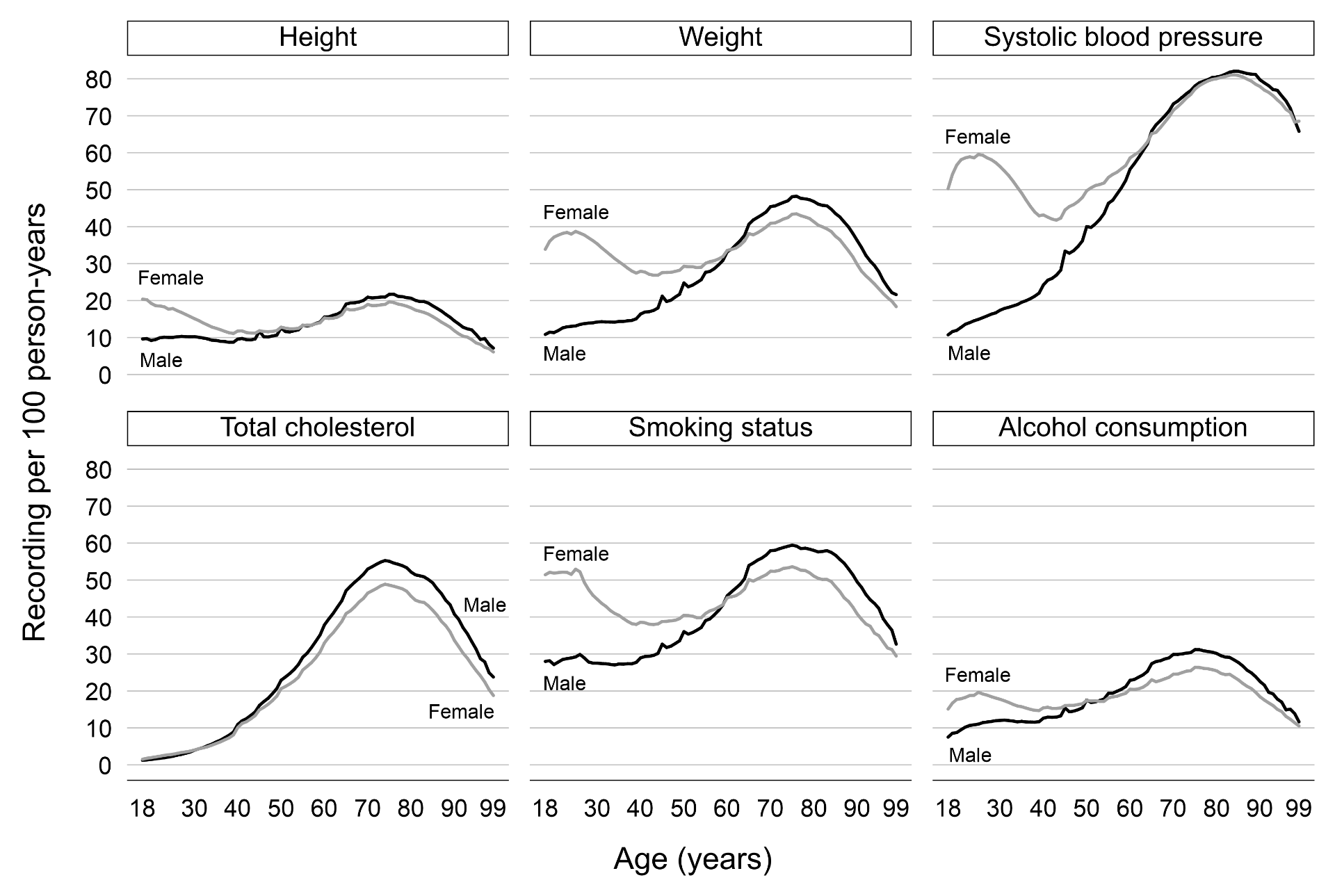
Figure 1. Number of records of each health indicator per 100 person-years by sex and age (in years).
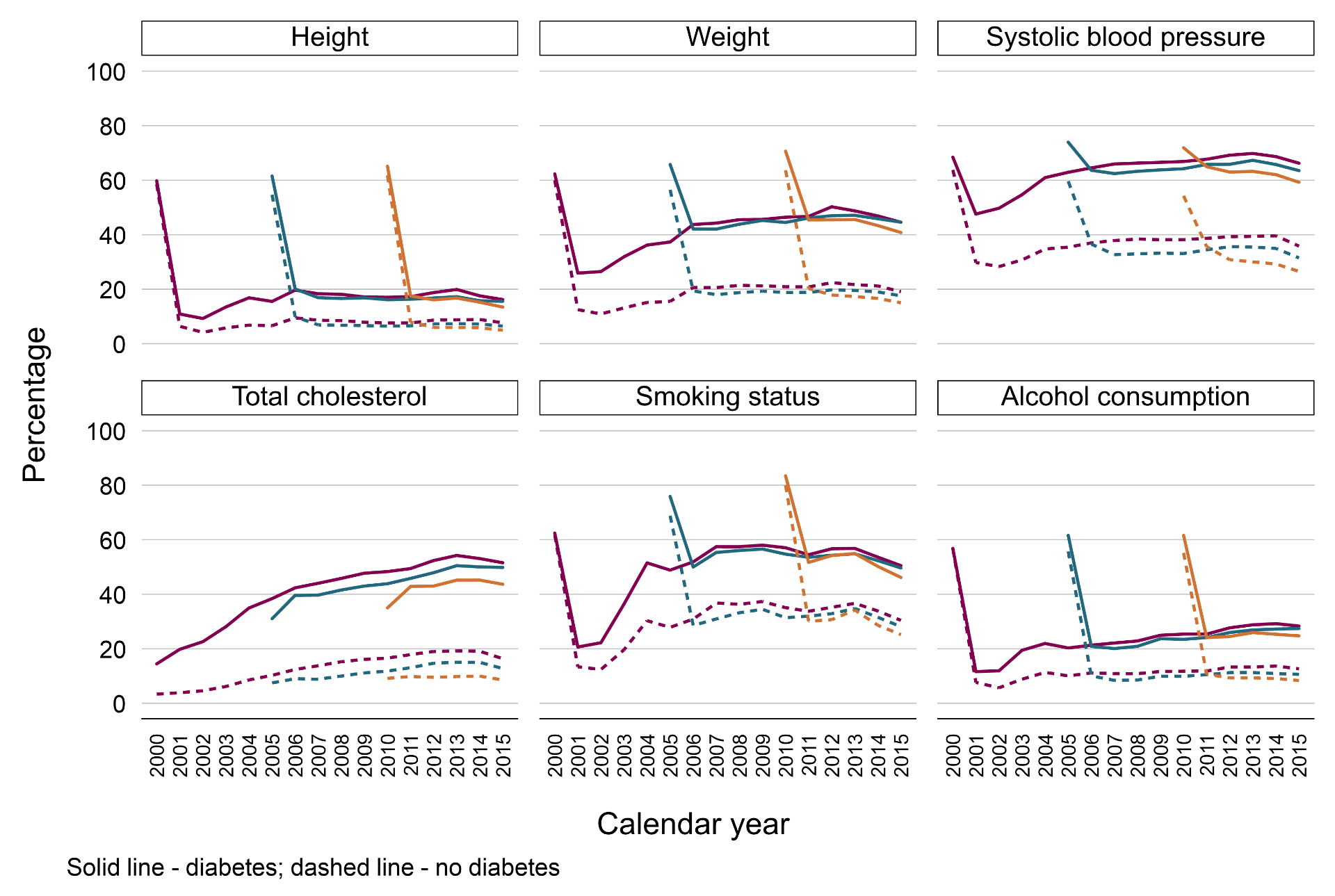
Figure 2. Percentage of individuals with a record of each health indicator in the 2000 (purple), 2005 (teal), and 2010 (orange) registration cohorts by calendar year and disease status.
Note. Solid line – diabetes; dashed line – no diabetes.








