As a MSc in Information Science student at the department I applied for the student systems developer position to help create an Open, Linked and Interactive Educational Resource for Bibliographic Data and was appointed in late September.
I could not summarize in a blog post everything I have learned so far but here are some highlights.
Semantic Web, Linked Data and RDF
Search engines have made the job of finding our way around the Web much easier. But we still have to go through the results of a search and take a few more steps until we get exactly what we want. That is because Web content is in a ‘human readable’ format and computers have a limited understanding of it. This understanding can be improved and there are several approaches to do so. One of them is the Semantic Web.
Honestly, I could not possibly explain better than the people from How Stuff Works what the Semantic Web is. Have a look, their Star Wars examples are insuperable.
Similarly, who could explain better Linked Data than Sir Tim Berners-Lee on his TED talk? He says Linked Data is about using identifiers for resources, those identifiers contain data in a standard format and, this is very important, relationships.
The standard format Berners-Lee talks about is Resource Description Framework (RDF). If you are interested in it, read the RDF primer or chapter 3 of Semantic Web Primer. Copies are available at UCL’s Science Library.
RDF allows to make statements, also called triples, composed of a subject (a resource), a predicate (a relationship) and an object (a value or another resource). Using the How Stuff Works example:
<AnakinSkywalker><isFatherOf><LukeSkywalker>
We are telling the computer that Anakin has a relationship ‘isFatherOf’ with Luke but we need to give the computer a bit more information. We know things that the computer does not know about this statement like:
- Anakin and Luke are both people and they are both male.
- Only males are called ‘father’ and in this context it describes the relationship with another person.
- Anakin is Luke’s father which means that Luke is Anakin’s son.
In RDF terms:
- Anakin and Luke belong to the subclass ‘Male’ of the class ‘Person’.
- Only resources belonging to the class ‘Male’ can have the property ‘isFatherOf’ (domain restriction) and only other resources that belong to the class ‘Person’ can be the objects of this property (range restriction).
- There should be another property named ‘isSonOf’ to explain the second relationship. Again it will have the domain ‘Male’ (a son can only be a male) and the range ‘Person’ (either a female or a male).
Classes, properties, domain restrictions and ranges can be defined in a RDF Schema (RDFS). RDF does not make any assumptions so the user can create any classes or properties.
SPARQL, which is the query language for RDF, is something else I have briefly had a look at. I will soon be learning about the practical side of publishing Linked Data as well.
BIBFRAME
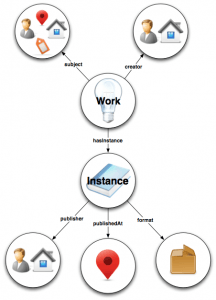
The Bibliographic Framework (BIBFRAME or BF) is the standard replacing Machine Readable Cataloguing (MARC). Since the late 1960s, MARC provided bibliographic records with a structure that allowed computers to interpret and exchange the data they contained.
The new standard is now focusing on the Web environment and its objectives, as pointed out on the primer document, are “to differentiate clearly between conceptual content and its physical manifestation, focus on unambiguously identifying information entities and leverage and expose relationships between and among entities”.
With BIBFRAME we will be representing the valuable metadata libraries held until now in databases as Linked Open Data. Hopefully, this will lead to users being able to find information easily, search engines to direct people to library resources and to allow innovative uses of the metadata sets, increasing their value.
BIBFRAME is what the project I am helping with focuses on. I have read much of the content available on the official site, tried the editor, the comparison service and the transformation service. I have gone through examples and tried to create my own BF records which has helped me to learn about the use of the vocabulary elements. I have also joined the BIBFRAME list serv and keep an eye on what people are saying about it on social media.
If you are interested in learning more about BIBFRAME I would strongly recommend to start by reading the primer document as well as the FAQ section, then check out the vocabulary description and have a look at the vocabulary category view. This video of Eric Miller’s keynote at the DCMI 2014 sums up quite nicely what BIBFRAME may mean for the library community in the future. It lasts 80 minutes but it is worth it.
—–
Natalia Garea Garcia (@ngarea) is studying for her MSc IS and is the Student Systems Developer for the Linked Open Bibliographic Data project, for which staff in the Department of Information Studies (Antonis Bikakis (Project Lead), Anne Welsh (Project Coordinator), Simon Mahony and Charlie Inskip) hold an E-Learning Development Grant. Further blog posts and reports will be published periodically. A key output of the project is collaborative co-learning between staff and students, and this blog post supports teaching today in INSTG004 Cataloguing in which Natalia, Antonis and Anne are sharing knowledge and practical experience with students on the MA LIS.
Image: Overview of the BIBFRAME Model, Library of Congress
Note: the appearance of the byline on this post is auto-generated, indicating that it was posted by Anne Welsh. Natalia Garea Garcia is the sole author of this piece.
Filed under Linked Open Bibliographic Data, MA LIS, MSc IS, Research Projects, Student posts
Tags: Anne Welsh, Antonis Bikakis, BIBFRAME, Charlie Inskip, ELDG, INSTG004, Natalia Garea Garcia, RDF, Semantic Web, Simon Mahony
No Comments »
 Close
Close

 Indexing and abstracting databases are key to producing good, robust research but they can be daunting and confusing and it is tempting to stick with the familiarity of Google and Google Scholar. To get some advice on searches for your assignments, come along to a search skills surgery, where you can pick up some tips and develop your confidence in using A&I databases.
Indexing and abstracting databases are key to producing good, robust research but they can be daunting and confusing and it is tempting to stick with the familiarity of Google and Google Scholar. To get some advice on searches for your assignments, come along to a search skills surgery, where you can pick up some tips and develop your confidence in using A&I databases.