 Close
Close

Research Integrity in an AI-Enabled World
By Samantha Ahern, on 5 April 2024
Over the last 15 months there has been much debate, hype and concern relating to capabilities of tools and platforms leveraging Large Language Models (LLMs) and media generators. Broadly termed Generative AI. The predominant narrative in Higher Education has been around the perceived threat to academic integirty and associated value to degrees. As such a lot of focus and discussion has focused on taught students, assessment design and “AI-proof” assessment. This has been coupled with concerns relating to the inability to reliably detect generated content, and the disproportionate number of false positives related to non-native English speakers text submitted to various platforms.
 However, despite the proliferation of Generative AI enabled research tools and platforms, numerous workshops offering increased research output productivity and publications asking authors to declare whether or not these tools were used in producing outputs there has been limited discussion with relation to staff and research integrity.
However, despite the proliferation of Generative AI enabled research tools and platforms, numerous workshops offering increased research output productivity and publications asking authors to declare whether or not these tools were used in producing outputs there has been limited discussion with relation to staff and research integrity.
Coupled with the publication of initial findings from a study on staff use of these tools by Watermayer, Lanclos and Phipps that included use to complete “little things like health and safety stuff, or ethics, or summarizing reports” and potential safety risks from fine-tuning models as reported in the Stanford Univeristy published policy briefing Safety Risks from Customizing Foundation Models via Fine-Tuning a workshop focusing on the interplay of Generative AI and research integrity and ethics was proposed as an AIUK Fringe event.
Research Integrity in an AI-Enabled World took place on Monday 25th March 2024. The aim was to explore how we think Generative AI enabled tools and platforms, could and should impact on the research process, and what the integrity and ethics implication are. Eventually aim would be to produce a policy white paper.
The event was organised so that there was a series of thought provoking talks in the morning, followed by a world-cafe style session in the afternoon. The event was held under the Chatham House Rule to enable open and frank discussion of the topic and arising issues.
The first set of talks predominantly focused on ethical issues. There were discussions on authorship, and the nature of authorship where multiple actors are involved e.g. training data creators, platform developers and prompters. Bias in image generation, reinforcing misconceptions and stereotypes. Culminating in a talk on the University of Salfords evolving approach to Generative AI and research ethics.
The second set of talks was focused on current capabilities, limitations and implications of using Generative AI enabled tools in the research pipeline, predomintly focusing on qualitative analysis. This session included a discussion around evidence synthesis and the need to find more efficient methods whilst maintaining reliability and a breadth of knowledge, and different approaches using “traditional” machine learning approaches versus use of large language models. Enhanced capabilities of Computer Aided Qualitative Data Analysis Systems and implications for methodological approaches were also introduced and discussed. The session concluded with a talk from Prof Jeremy Watson about the work currently being undertaken by the UK Committee on Research Integrity’s AI working group, of which he is member. Key themes currently under consideration by UKCORI are:
- Governance
- Roles and Responsibilities
- Skills and Training
- Public Understanding and Expectations
- Attribution and Ownership – IP, etc.
- Understanding Data Inputs and Models
- Need for Research in AI and Integrity
During the world-cafe session participants addressed the following questions:
- What do we mean by Research Integrity in an AI-Enabled Research Environment?
- Are there degrees of Research Integrity based on discipline and how embedded AI use is in the research process?
- What are the key ethical and legal considerations?
Including the following participant proposed questions:
- Generative AI is extremely good at in-filling uncertainty, where details of images become filled with bias. Should the responsibility of bias be equally on a prompter who enables this by omission?
- Recalibration of government and private funded RI in AI? Isn’t this the foundation of biases for RI?
Outputs from the world cafe session will be analysed over the next few weeks, and workshop participants were invited to contribute to the development of workshop outputs.
Key themes that emerged from the event include:
- Transparency
- Criticality
- Responsibility
- Fitness for purpose
- Data protection and privacy
- Digital divide – privilege and harms
- Training – education
 The workshop was well received by participants, with the participants rate their overall experience of the event as 4.71 out of 5.
The workshop was well received by participants, with the participants rate their overall experience of the event as 4.71 out of 5.
The speaker sessions were rated as very good by over 70% of participants. With the world cafe being mentioned as a highlight of the event.
As the proposer, organising and the host of the event I can’t help but still wonder:
- Can we ethically and with genuine integrity use tools which are fundamentally ethically flawed?
- Why are we accepting of these issues?
- How should we be pushing back?
I will leave you with these words from Arudhati Roy with which I opened the event:
Role models, outreach and changing the future of STE(A)M
By Samantha Ahern, on 20 December 2023

STE(A)M is for everyone, so why isn’t that reflected in the demography of STE(A)M professionals?
Sadly, when we look at the prevailing media representation and social narrative around STE(A)M it’s not surprising. Which, is why, events like the one I recently supported at Samuel Whitbred Academy organised by STEMPoint are incredibly important.
Over the course of the day I supported girls from four different secondary schools undertaking two computing challenges, one focused on coding, the other on robotics. In addition to the challenges, the participants also had the opportunity to hear from the STEM Ambassadors, most of them women, supporting the event about our careers, why and how we got into STEM.
This was a key part of the event as it enabled them to learn more about the different types of STE(A)M careers available, pathways into those careers and the diversity of the people working in them.
It is often said that you can’t be, what you can’t see. You also can’t be what you don’t know about. This is why since 2015 I have been a STEM Ambassador.
During this time I have supported a number of events requesting support via the STEM Learning platform, featured in a STEMettes Christmas Calendar, been profiled for BCS Women and designed and delivered some RI Masterclasses. On a more subtle level I use my full first name on publications and when public speaking, re-emphasising that I am a woman in STEM.

The event at Samuel Whitbred Academy was a lot of fun, I always enjoy seeing students engaging with a STEM challenge. Especially seeing young women grow in confidence in their abilities and seeing computing as a space for them.
Unsurprisingly I spent most of the day supporting the robotics challenge. It was fantastic to see them rise to the challenge, and in some cases go beyond the extension task. I hope to support further events in 2024.
I strongly recommend becoming a STEM Ambassador to my colleagues, it really does make a big difference to the participants.
Randomising Blender scene properties for semi-automated data generation
By Ruaridh Gollifer, on 12 December 2023
Blender is a free and open-source software for 3D geometry rendering. Uses include modelling, simulation, animation, virtual reality applications, and more recently synthetic datasets generation. This last application is of particular interest in the field of medical imaging, where often there is limited real data that can be used to train machine learning models. By creating large amounts of synthetic but realistic data, we can improve the performance of models in tasks such as polyp detection in image guided surgery. Synthetic data generation has other advantages since using tools like Blender gives us more control and we can generate a variety of ground truth data from segmentation masks to optic flow fields, which in real data would be very challenging to generate or would involve extensive time consuming manual labelling. Another advantage of this approach is that often we can easily scale up our synthetic datasets by randomising parameters of the modelled 3D geometry. There can be challenges to make the data realistic and representative of the real data.

The Problem
The aim was to develop an add-on that would help researchers and medical imaging experts determine which range of parameter values make realistic synthetic images. Prior to the project, the dataset generation involved a more laborious process of manually creating scenes in Blender with parameters changed manually for introducing variation in the datasets. A more efficient process was needed during the prototyping of synthetic dataset generation to decide what range of parameters make sense visually, and therefore in the future, to more easily extend to other use cases.
What we did
In collaboration with the UCL Wellcome / EPSRC Centre for Interventional and Surgical Sciences (WEISS), research software engineers from ARC have developed a Blender add-on to randomise relevant parameters for the generation of datasets for polyp detection within the colon. The add-on was originally developed to render a highly diverse and (near) photo-realistic synthetic dataset of laparoscopic surgery camera views. To replicate the different camera positions used in surgery as well as the shape and appearance of the tissues, we focused on randomising three main components of the scene: camera transforms (camera orientation and location), geometry and materials. However, we allowed for more flexibility beyond these 3 main groups of parameters, implementing utilities to randomise other user-defined properties. The software also allows the following features: 1) setting the minimum and maximum bounds through an input file, 2) setting a randomisation seed for reproducibility, 3) exporting output parameters for a chosen number of frames to an output file. The add-on includes testing through Pytest, documentation for users and developers, example input and output files and a sample Blender scene.
The outcomes
Version 1.0.0 of the Blender Randomiser is available under a BSD 3-Clause License. The GitHub repo is public where the software can be downloaded and installed with instructions provided on how to use the add-on. Examples of what can be produced in Blender can be found at the UCL Research Data Repository (N.B. these examples were produced manually prior to completion of this project).
Developer notes are also available to allow contributions.
—
k-Plan now available to researchers!
By Sam Cunliffe, on 11 December 2023
One of ARC’s longest-running collaborations is with the Biomedical Ultrasound Group. Over the past three years, we’ve been developing a graphical user interface to simulate ultrasound treatment plans!

This software is called k-Plan, and licences are now available for sale through UCL’s commercial partner, BrainBox (who also sell ultrasound transducers).
If you’re interested in medical ultrasound, and think this software might help you: you can read the full UCL press release, or you can see some more snapshots of k-Plan in action.
The people behind the work…
Our collaboration is managed and led by Bradley Treeby. As well as me, there’s a full roster of research software engineers who’ve worked hard at various times over the last three years to make this happen:
- Panayiotis Georgiou, ex-UCL now ARM.
- Timothy Spain, ex-UCL now NERSC, 🇳🇴.
- Ilektra Christidi, ARC, UCL.
- Alessandro Felder, ARC, UCL.
- Orod Razeghi, ex-UCL now University of Cambridge.
- Idil Ozdemir, ARC, UCL.
- Connor Aird, ARC, UCL.
We also have collaborators from the Brno University of Technology who work behind the scenes on the middleware and back-end of k-Plan and run the planning simulations in the cloud.
First Julia workshop at ARC
By David Pérez-Suárez, on 15 November 2023
Last Friday (the 10th of November) we run our first ever Julia workshop. After years of having an expert in our team – Mosè – who has been introducing the rest of the team to this wonderful language and even convinced some collaborators to use it on their projects, we’ve done the jump to teach it to the UCL community.
 This first workshop was limited to a reduced number of learners (10-12). Seven of which attended (most of them physicists!), with our team of three (myself instructing, with Mosè and Tuomas helping — also all physicists 😅) made the learners’ experience very positive.
This first workshop was limited to a reduced number of learners (10-12). Seven of which attended (most of them physicists!), with our team of three (myself instructing, with Mosè and Tuomas helping — also all physicists 😅) made the learners’ experience very positive.
Originally, we were going to use the Carpentries Julia lesson available in the incubator. However, Mosè and I decided against it as the expected previous knowledge was higher than what we were aiming for. Therefore, we created our own lesson!
Our lesson started with the basics, different types of numbers, strings and how all them fit in the family of types in Julia. We introduced some of the quirks Julia surprises you with when you come from a different language. This was key in our lesson! We started to write a function as if it was Python — which was what we expected to be the most familiar for our cohort. From there, we were introducing new concepts and syntax to make our code more “julianic” (I’ve come up with that term, so it may not be the one used by the Julia community). We covered the basics (types, function, conditionals, loops and plotting) during the morning session. After lunch, we went to introduce how to use other libraries to solve polynomials and ordinary differential equations. We even introduced unit testing and had time to learn how to work with CSV files with DataFrames and gave a quick overview of Pluto.
During the preparation of the material and the class, I was constantly supported by Mosè, bouncing lots of ideas and suggestions. We’ve even found a bug in one of the libraries we were going to use that they fixed instantly after Mosè reported it.
The class went smoothly. We encountered some problems with the installation of Julia and some unexpected slowness when installing libraries (we reported it after the workshop, and it was also fixed straight away!). This is some of the feedback we’ve received at the end of the day:
- Great course, learned a lot.
- The course has been great. The pace is good and it allows us to ask any questions we have.
- Comparison’s to Python really helped me appreciate the advantages of Julia. Paper plane example was great.
- Very good course, covered all the right topics for a 1-day intro session.
Personally, I don’t remember a class that has gone so well! With very little difficulties, covering everything we were planning to do and answering very interesting questions from our learners. It may have been due to the small number of learners, or because of their previous programming experience, or the similar background across all of them, or maybe, it’s because Julia is easy to learn 😉. Whatever reason it is, I really want to repeat it, with a larger class and a more varied background of learners. There’s no reason for only letting the physicists have fun with Julia, right.
So, if you are interested in learning Julia, be sure that we will repeat more sessions like this one! This may be too basic for you? Don’t worry, we are also planning to run a more advanced workshop focused on Julia for HPC during Term 2’s reading week. Keep an eye out for our future announcements.
Now that we have started, we won’t stop!
Using continuous integration efficiently
By Matt Graham, on 3 November 2023
Use of continuous integration (CI) is an important part of creating robust and reproducible research software, however running automated jobs on services such as GitHub Actions and GitLab CI/CD comes with an associated energy, and so environmental, cost.
As an example, in the 30 days from 2nd October to 1st November 2023, the UCL/TLOmodel repository ran GitHub Actions workflow jobs which used 1937 hours of runner time. As a (very rough) back-of-the-envelope estimate, assuming an average runner power consumption of 12W[1] this equates to a total monthly CI energy usage for this project of 23kWh, which is about 10% of a typical UK’s households monthly electricity usage or the monthly energy usage of around 8 UCL employee’s laptops[2].
Below are some simple ways to reduce GitHub Actions and GitLab CI/CD runner usage without compromising the gains that automated testing and deployment brings. These approaches also have the side benefit for private GitHub repositories of reducing usage of the free Actions minutes quota.
- Automatically cancel redundant jobs
For jobs triggered by pushing commits to a pull or merge request branch, we may push new commits and trigger new job runs while previous runs are still in progress. Typically we will only care about the job results on the latest commit, and so the previous job runs will be redundant. Theconcurrency.groupandconcurrency.cancel-in-progressproperties in GitHub Actions workflows can be used to automatically cancel already in progress job runs at different grouping levels – for example for workflows triggered for the same pull request, branch or tag. In GitLab, jobs which have theinterruptibleproperty set totruewill be automatically cancelled when the Auto-cancel redundant pipelines project setting is enabled. Both GitHub and GitLab also allow manually skipping job runs when pushing new commits by including a token such as[skip ci]or[ci skip]in the commit message. - Use filters and rules to only run jobs when needed
Commonly some checks are only relevant to a subset of the files in a repository. For example if a branch only involves changes to a Markdown README file we probably do not need to run a test suite for the source code in a repository. In GitHub Actions we can use the optionalpathsandpaths-ignoreproperties of thepushandpull-requesttriggers to only run workflow jobs when the files changed do or do not match one or more patterns. Similarly in GitLab we can use rules to set conditions on a when a job runs, with specifically therules:changesproperty allowing limiting runs to when files matching specified patterns are changed. It may also make sense to have jobs only run when pull requests are no longer drafts and are marked as ready to review. This can be achieved in GitHub Actions using a combination of theon.pull_requests.typesproperty and using anifcondition on the job that checksgithub.event.pull_request.draftisfalse. - Set the scheduled job frequency appropriately
Both GitHub Actions and GitLab CI/CD pipelines allow running jobs on a schedule usingcrontabsyntax. While we sometimes refer to nightly jobs, it is worth considering carefully what the appropriate frequency is for such scheduled jobs based on the use case and wider context of the project, and whether running jobs at for example a weekly frequency might be sufficient. For example running daily jobs to check whether tests for a package pass against the latest compatible versions of upstream dependencies may make sense for a a package with a large userbase and development team where breaking changes in upstream packages are both likely to be encountered in practice quickly, and where there is likely to be sufficient developer capacity to resolve the issues in a similar timeframe. On the other hand for a package with fewer users and contributors, having a test job identify such breaking changes at a weekly frequency may be sufficient. - Cache job dependencies
A common step in CI jobs is setting up dependencies on the runner, often using a language specific package manager likenpmorpip. Rather than redownloading and building dependencies afresh on each run, we can use caching features to reuse the dependencies built in previous jobs (providing the new run uses the same versions of dependencies). The GitHubcacheaction provides a generic approach for performing caching in GitHub Actions jobs, while language specific setup actions such assetup-pythonhave built in support for setting up dependency caching. GitLab similarly provides support for caching dependencies. - Set timeouts to avoid misbehaving jobs running for long times
The default timeout for GitHub Actions jobs is 6 hours. If you expect a job to run in much less time than that, setting a more conservative timeout can avoid misbehaving jobs which hang or run very slowly, from inadvertently using a large amount of runner time. The default timeout on GitLab is shorter at 60 minutes but can similarly be adjusted. - Chain jobs intelligently and fail fast
Commonly we will run an assortment of test and checks as part of CI workflows with a corresponding wide range of run times. Code formatting and linting checks will typically be the quickest to run, while test suites may contain both quicker unit tests as well as integration and system tests which can take longer to run. Ensuring faster running checks and tests run first, and halting further jobs from running if these fail, will avoid wasting compute time running slow tests unnecessarily before changes to fix the faster running checks are made. Taking this one step further, for very quick checks such as linting and formatting, frameworks likepre-commitcan be used to ensure checks are run automatically when committing changes, reducing the chance of CI jobs failing and needing to be rerun in the first place. In GitHub Actions thejobs.<job_id>.needsproperty can be used to specify that other jobs must successfully complete before another job runs. When running a matrix strategy job which creates one job run for each of a set of configurations (corresponding to for example different versions, operating systems or groups of tests) thejobs.<job_id>.strategy.fail-fastproperty can be set totrueto cancel any other still in progress job runs in the matrix if a single run fails. GitLab pipeline jobs also have aneedsproperty for specifying dependencies.
-
Estimating the power usage of a CI job runner is complicated as typically jobs will be run on virtual machines (VMs) on cloud-hosted servers, with generally there being multiple VMs running in parallel on each server and potentially multiple job runners per VM. The analysis in Aldossary and Djemame (2019) suggests a VM with 4 virtual central processing units (CPUs) running on a host with eight-core Intel Xeon E3-1230 V2 CPU and 16GB of DDR3 RAM when running with an active load with 80% CPU utilization can be attributed a mean power consumption of around 40W (see Figure 7). If we assume four job runners per VM (one per virtual CPU) this corresponds to around 10W per runner. To account for the additional power overhead for data centre infrastructure such as cooling, we assume a power usage effectiveness of 1.2 (based on figures provided by Microsoft for Azure), giving an average overall power draw of 12W per runner. ↩︎
-
This is based on an assumption of an average power draw of 20W (under a mix of idling and working at load) for a Dell Latitude 5410 laptop with a 36.5 hour working week and four weeks in a month giving an estimate of 2.92kWh used per laptop per month. ↩︎
Simulating light propagation through matter.
By Sam Cunliffe, on 31 October 2023
Observing how light interacts with materials allows us to develop non-invasive medical imaging techniques, that rely on these interactions to assemble an image or infer an appropriate diagnosis.
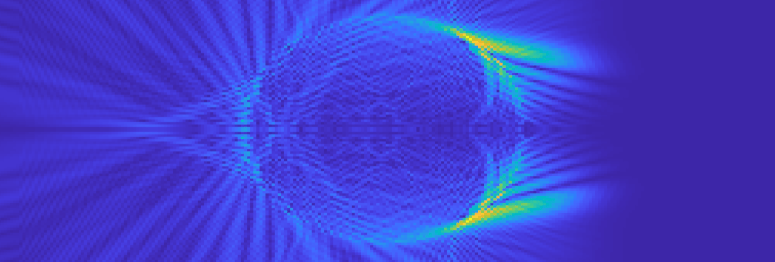
Light interacts with materials in many different ways. One of the most commonly observed interactions is dispersion; which causes white light to split into individual colours, creating phenomena like rainbows (light from the sun dispersing through raindrops). Another commonly observed interaction is refraction; which causes light to change direction as it passes between two materials, responsible for straight objects like straws appearing to be disjointed when placed into water. To completely describe what is going on in these interactions, we have to use a system of equations known as Maxwell’s equations. We also have to consider some additional parameters that describe the particular material(s) that the light is interacting with. In their most general form, Maxwell’s equations are very complex but have the advantage that almost all materials and interactions can be modelled by them. Solving these equations is, in general, impossible to do with pen and paper, so we need software to do this for us.
Software like this has a wide variety of applications in biomedical optics; notably optical coherence tomography (non-invasive medical imaging of the eye), multiphoton microscopy, and wavefront shaping. For example; we can use this software to model light propagating in the retina: simulating a retina scan. Then we can perform a retina scan for a patient in real life, and use our simulation to better understand the scan. Retinal scans often hint at a particular change to the retina, without being definitive, in the early stages of disease. We can use our simulation to test what types of changes to a retina can lead to observed signatures in an image and therefore help in achieving a diagnosis.
The Problem
In collaboration with the UCL Medical Physics and Biomedical Engineering department, developers from ARC have worked to open up a legacy C and MATLAB library which simulates light propagating through matter. This software was initially developed as part of a PhD thesis approximately 20 years ago and has been continuously developed since then. However, the need to rapidly answer research questions led to the code becoming less sustainable and harder for others to use. Whilst the core functionality was already there; the library needed updating to a more modern language and aligning with the FAIR4SW principles.
What we did
The aim of the project was to be able to provide users with a program that they can give custom input which describes the material they want to simulate, pass this to the software and receive an output they can use in further analysis. We wanted users not to have to worry about the internal workings of the software; only having to download the library code, build and install it once, and be ready for future analyses. We used modern build tools to standardise the build and install of the software, we aimed to make our instructions as straightforward and operating-system-independent as possible. We also set up automated testing of the software and wrote example scripts that users can modify to easily create input files in the correct format.
The outcomes
Version 1.0.1 of the Time Domain Maxwell Solver (TDMS), is now available under a GPL-3.0 license. You can download from GitHub, and install and run on all operating systems. The project has a public-facing website and a growing collection of examples. We also have developer documentation so anyone can contribute in the future.
TDMS 1.0.1 now has a number of new features, including the option to switch between different solver methods (how the simulation is performed), select custom regions over which to compute (to save wasting computation time), and the ability select different techniques for extracting output information through interpolation.
The ARC software engineers were a joy to work with. They brought knowledge of modern software engineering practice and quickly understood the code, and the underlying physics, as required to very effectively re-engineer the code. This collaboration with ARC will hopefully allow for a new range of users to access TDMS and significantly increase its impact.
—
RSE and Education for Sustainable Development: A Call to Action
By Samantha Ahern, on 12 September 2023
RSECon23 opened with a keynote from Gael Varoquaux, introducing themes synergistic to my conference workshop “How do we design and deliver sustainable digital research education”.
The actual theme of the workshop, what role(s) does RSE have to play in Education for Sustainable Development probably wasn’t what most participants were expecting. However, there were some very good conversations and ideas for action.
The workshop opened with two questions:
1. What does Sustainable mean to you?
2. What does Education for Sustainable Development mean to you?
These set the scene for the discussion in the session.
Key definitions and the SDGs
Sustainability
“meeting the needs of the present without compromising the ability of future generations to meet their own needs.”
UN, 1987
Sustainable Development
“An aspirational ongoing process of addressing social, environmental and economic concerns to create a better world.”
Advance HE / QAA 2021
Education for Sustainable Development
“The process of creating curriculum structures and subject-relevant content to support sustainable development.”
Advance HE / QAA 2021
The workshop participants were introduced to the 17 UN Sustainable Development Goals and asked to consider which are areas for development in RSE and which of these areas can we affect through education?
There was a general consensus that almost all are related in some way to RSE activity and impact that activity. The most notable being SDG 4: Quality Education.
Through RSE led education activity it was felt that the SDGs that could be affected were:
- Goal 3: Good Health and Wellbeing
- Goal 4: Quality Education
- Goal 5: Gender Equality
- Goal 8: Decent Work and Economic Growth
- Goal 9: Industry, Innovation and Infrastructure
- Goal 10: Reduced Inequalities
- Goal 11: Sustainable Cities and Communities
- Goal 12:Responsible Consumption and Production
- Goal 13: Climate Action
For Goals 16 (Peace, Justice and Strong Institutions) and 17 (Partnerships For The Goals) it was unclear as to how these would apply.
Barriers and Opportunities
The discussion then focused on barriers to having an impact on the SDGs but also what opporunities we had for making a positive difference.
Barriers
Key themes from the discussion on barriers were:
- Resources: time, people, data sets
- Funding
- Lack of training, confidence in education skills
- Lack of recognition
- Lack of support / mentorship
Opportunities
Key themes from the discussion on opportunities were:
- Ability to design our own materials and select data sets
- Work collaboratively, as a community
- Ability to raise awareness of issues
- Access to experts from across our institutions
- Access to education related CPD (if in a university setting)
- Our learners want to learn
- Our educators are passionate about their work
Although there are some well recognised barriers, there is also a lot of opportunities and connections we can leverage to make change.
The Call to Action
The workshop concluded with a design task to identify concrete steps we could take to address the barriers and leverage the opportunities.
The calls to action were:
- Never teach alone
- Enables different ways to explain
- Could lead to a variety of role models
- Less pressure
- More perspectives
- Broader variety of disciplines
- Different background knowledge
- Encourage those who found it difficult to return as helpers and instructors
- Humanise the educators
- Introductions
- Live coding
- Coding confessiona
- Co-development of lesson materials
- Share ideas and examples
- Examples from different domains
- Talk to learners
- What is needed?
Most importantly, we are community and should leverage that community to learn from and support each other.
So, let’s work together to make a positive change!
Two Senior RSE posts available at UCL ARC
By Jonathan Cooper, on 27 October 2022
The UCL Centre for Advanced Research Computing (ARC) is recruiting for two permanent Senior RSE members, with a closing date of 6th November 2022. One post has a focus on supporting UCL East, while the other is intended to be more teaching-focused, but any individual matching the job description is encouraged to apply. The most important attribute is an enthusiasm for reproducible, reliable and sustainable computational research!
ARC is UCL’s centre for digital research infrastructure and innovation: the software, supercomputers, data, and skills that underpin computational science and digital scholarship across the college. We are an innovative hybrid: a professional services department that delivers reliable and secure infrastructure and services to UCL research groups, and a laboratory for research and innovation in the application of advanced computational and data-intensive research methods, working in partnership with academics from all fields.
You will design, extend, refactor, and maintain scientific software in all subject areas, providing expert software engineering consulting services to world-leading research teams, training researchers in programming best practices, and working with scientists and scholars to build software to meet new research challenges. Whether this means using Python to build up a database of ancient Sumerian writings, parallelising Fortran codes for surface catalysis simulations, analysing live healthcare data within hospitals, or creating an MPI-distributed particle filter for data assimilation in Julia, we do it all. With such a varied job we don’t expect our candidates to know it all from the start. It is an excellent opportunity to develop new skills, spending time to study both the research areas we support and the specialist technologies applied.
The team is friendly and diverse, currently with over 45 research technology professionals collaborating on research projects and teaching. All our positions are permanent, on open-ended contracts, and enjoy good opportunities for personal development and career progression within the group, in both technical and managerial tracks. We support a range of flexible working options, including part-time appointments at all levels.
For more details of the vacancies and to apply check out the full adverts linked above. The closing date will be 6th November 2022, with interviews taking place using Microsoft Teams or in person between 17-25 November. The salary range is from £47,414 – £55,805 per annum.
Further vacancies across all ARC’s professions will be coming soon!
Hack the (ARC) Teaching workshop
By David Pérez-Suárez, on 4 July 2022
Two weeks ago (20th – 23rd June) we ran an internal workshop in our group to reflect about our teaching activities. As any good workshop, it also included a fun hack day at the end to work on pet projects or ideas that we haven’t had the time to work on it before. This is a summary of these four days and a reflection for the future.
The workshop was set with two main purposes: review all the teaching activities we are involved, and learn some techniques to become better teachers. The workshop was attended by roughly 8 people every session, this contributed to allow everyone to participate. The event was fully hybrid, with roughly a 50-50% participation of people joining physically and remotely (the trains and tube strike shifted the participation towards a 30-70% towards the end of the week). Thanks to the big screen and the semi-separated areas we have in our collaboration space, together with how the workshop was run with smaller physical and virtual small groups, contributed to a nice flow of the workshop.
Each day of the workshop was broken into two 2-hour blocks, one in the morning from 10:00 to 12:00 and one in the afternoon form 14:00 to 16:00. This helped to disconnect a bit, catch up with other commitments or have time to enjoy lunch in the park while recharging our solar batteries.
In terms of tooling, we used MS Teams as the conferencing tool (our calendars and the big screen are linked to it) – we also explored the breakout rooms feature it provides; HackMD and Etherpad for note-taking; Google’s Jamboard for collaboratively moving cards in a digital medium; IdeaBoardz to collect feedback; and tried (with only partial success) Visual Studio Code’s Live Share to pair-program during the hack day.
Now that the logistics and tooling has been explained, let’s dive into the content of the workshop.
The workshop started with a short review of the Carpentries instructor training lessons. That workshop lasts two full days, and this session lasted only two hours. Therefore, many things were not covered (like practising the teaching), however, we covered some basics about how learning works and how to create a positive learning environment. As any Carpentries workshop, they are full of activities and discussions, and we had good and interesting discussions. The afternoon of that day, we spend it discussing a set of uncomfortable scenarios that may happen during a teaching activity. These scenarios were created by Yanina Bellini Saibene for Metadocencia and translated by J.C Szamosi. They are a very useful resource to explore before they manifest in a real situation. The scenarios were distributed between the different small groups and then shared with the bigger group our suggested actions. Of course, sharing it in the bigger group was also a source of new point of views and ideas. We highly recommend doing this exercise to everyone who takes part in any teaching activity! The day finished with a review of the Science of Learning paper. As with the previous exercise, we distributed the sections across us and discuss it first in small groups and then as a whole. This is a nice quote about the paper from Sarah in our team:
I want to print this out and stick it all over my office so I can see it whenever I teach.
The second day was focused on our teaching activities and an overview of Submitty, the autograding tool we use in a couple of master courses we teach. We started with a set of lightning talks (aiming for 1 minute each, but all of us overran a bit) for each teaching activity we are involved in. Each talk has to describe the teaching activity with its topics, the audience to whom it is aimed to, the format, what is going well and what can be improved, and finish it with the challenges presented for next year – all that in one minute! We had 13 talks, some of these talks are from courses or workshops we run once a year, others are about courses that happen multiple times. Two of them were from the UKRI Data Science Training in Health and Bioscience (DaSH) projects we are involved with: IDEAS and Learn to Discover. The last one was a short summary of the teaching activities from our friends at Digital Education. The afternoon was focused on Submitty. First with an overview of how the system looks from the different point of views (student and instructor) and then how to set up the exercises. We completed the day with an exercise about thinking how to plan the autograding of two questions from past assignments. The main conclusion of this exercise was that for autograding to work, we need to be more specific on what we ask the students. This, however, may have its disadvantages as it limits the freedom of how the students may approach a problem.
The third day was an ABC Learning Design workshop led by Nataša Perović from UCL’s Office of the Vice Provost Education & Student experience. The workshop starts with an overview of the different learning activities types as described in Diana Laurillard’s work “Teaching as a design science”. We spent the practical side of the workshop, focusing on three of our courses. It was a very useful exercise that we should do more frequently to keep improving and fine-tuning our courses. In the afternoon, we learnt how to migrate our notes from Jamboard into the Learning designer tool from UCL’s Knowledge Lab at IOE. One cool feature that Nataša demonstrated to us is how our Learning Design structure can be exported into Moodle.
The last day was the hack day. We have a collection of mini-projects that we would like to work on, but that normally get postponed till we have the time… Well, finally the time arrived! We tackled four of these projects, two were completed quite quickly, and the other two got started (and that’s sometimes the harder bit!) and hopefully the inertia keeps them moving to a complete state soon. One project that involved an analysis of students grades included a good discussion at the start about the ethics and privacy of the project. This helped to make some decisions of which dataset we were going to use (e.g., the anonymous dataset provided by Moodle before the marks get released), and future ideas about how to clarify to the students how the assignments get graded anonymously.
That was how we’ve spent four days last week learning how to improve our teaching, reflecting on what we’ve done so far and planning what we can do to have better courses in the future. After the positive feedback and seeing how useful a focus week without other distractions can be, we may make this a recurrent annual activity!