 Close
Close

Join us for International Love Data Week!
By Rafael, on 7 February 2024
Guest post by Iona Preston, Research Data Support Officer.
Next week (February 12-16), we’re excited to be celebrating International Love Data Week. We’ll be looking at how data is shared and reused within our UCL and academic community, highlighting the support available across UCL for these initiatives. This year’s theme, “My Kind of Data,” focuses on data equity, inclusion, and disciplinary communities. We’ll be blogging and posting on X throughout the week, so please join us to learn more.
Here’s a sneak preview of what’s coming up:
- Did you know the Research Data Management team can review your data management plan and support you in publishing your data in our Research Data Repository? Find out more about our last year in review with Christiana McMahon, Research Data Support Officer.
- Have you met any members of our Data Stewards team? James Wilson, Head of Research Data Services, will be explaining how you can collaborate with them to streamline the process of managing and preserving your data, thereby supporting reproducibility and transparency in your research.
- Are you seeking tools to support best practices in data management for your specific discipline? We have some suggestions from Iona Preston, Research Data Support Officer.
- You may have heard of FAIR data – but what does that mean in practice? Join Research Data Steward Shipra Suman and Senior Research Data Steward Victor Olago as they discuss projects where they’ve supported making data FAIR.
- And, finally, to round off the week, Senior Research Data Steward Michelle Harricharan will talk about a project the Data Stewards are carrying out to better support UCL researchers in accessing and managing external datasets.
We look forward to engaging with you throughout the week and hope you enjoy learning more about research data at UCL.
And get involved!
![]() The UCL Office for Open Science and Scholarship invites you to contribute to the open science and scholarship movement. Stay connected for updates, events, and opportunities. Follow us on X, formerly Twitter, and join our mailing list to be part of the conversation!
The UCL Office for Open Science and Scholarship invites you to contribute to the open science and scholarship movement. Stay connected for updates, events, and opportunities. Follow us on X, formerly Twitter, and join our mailing list to be part of the conversation!
Shaping the Future: OOSS Initiatives and Goals for 2024
By Rafael, on 26 January 2024
Following our blog post last week, where we reflected on the achievements of 2023, this week we wanted to look forward and share our plans for 2024. From championing open research practices to fostering inclusivity, transparency, and collaboration, the UCL Office for Open Science Scholarship (OOSS) teams are gearing up for an exciting new year!
OOSS 2024 Initiatives:
Annual Conference: Anticipate the return of the UCL Open Science Conference after Easter, promising an exciting and engaging program. Stay tuned for details as we continue to drive conversations on open science, sustainability, and inclusivity in research practices.
Authorship Overview: Building on the success of the 2023 conference, OOSS is preparing to release an overview of best practices in authorship. The focus on equity in authorship during a dedicated workshop last year has further contributed to the development of a UCL statement on Authorship, showcasing our commitment to fostering fair and inclusive authorship practices.
UCL Open Research Train the Trainer Course: OOSS proudly supports the UCL Open Research Train the Trainer course, a key part of the UKRN Open Research Programme. This course aims to empower participants with the knowledge and skills needed to champion open research practices, contributing to the broader mission of advancing openness in academia and beyond.
Open Science Website Overhaul: Over the summer, the office has ambitious plans for an overhaul of the Open Science website. This initiative aims to enhance user experience and engagement. As part of this revamp, case studies from the community will be gathered, providing an opportunity for voices within UCL to contribute to the narrative of open science. Watch out this space!
Research Data Team:
Love Data Week 2024: In February 2024, the Research Data Team will celebrate Love Data Week, a dedicated time to showcase impactful data from the academic community underscoring the team’s commitment to recognising the value of open data practices and promoting its significance in research. Join us!
Training and Review Services: The Research Data Team is dedicated to enhancing accessibility in 2024. One of the key initiatives involves the redesign of online training for Writing Data Management Plan providing a more user-friendly experience for researchers to access resources and guidance efficiently. Additionally, throughout the year, the team will offer training sessions and review services on data management plans. This ongoing support ensures that researchers align with funders’ criteria and best practices, contributing to the overall improvement of data management within the UCL community.
Best Practice Guidance for Metadata Records: An important focus next year will be the development of best practice guidance for creating high-quality metadata records. These records play an essential role in enhancing the findability and reusability of research data. To facilitate this, the team is creating user-friendly video guides, making it easier for researchers to grasp the essentials of metadata creation and promoting adherence to best practices.
Citizen Science Team:
Community Building: The Citizen Science Team at OOSS is committed to community building in 2024. The focus is on expanding the UCL Citizen Science community, fostering connections among researchers and communities passionate about citizen science initiatives. A landmark initiative will be the hosting of the inaugural UCL Citizen Science Community event. This event provides a platform for community members to come together, share experiences, and explore collaborative opportunities. Stay tuned and participate!
Principles for UCL Citizen Science Projects: The Citizen Science Team recognizes the importance of establishing clear principles for UCL Citizen Science projects. In 2024, efforts are underway to articulate these principles, providing a framework that ensures the ethical, inclusive, and impactful execution of citizen science initiatives. These principles aim to guide project leaders, participants, and collaborators in creating meaningful contributions to both research and public engagement.
Establishing a Citizen Science Support Service: To further support the UCL community’s engagement with citizen science, the team is working on establishing a dedicated Citizen Science Support Service. This service will serve as a central hub for resources, guidance, and assistance related to citizen science projects. The team is also compiling an enhanced list of support resources for citizen science. This will include a diverse range of materials, from guidelines and toolkits to success stories and best practice examples. By consolidating these resources, the team intends to provide a valuable repository to guide researchers and community members involved in citizen science projects. While this is underway, we encourage you to explore the available resources and training materials on our website!
Open Access:
Support and Funding for Long-Form Outputs: In 2024, the Open Access Team is committed to extending support and funding to authors working on long-form outputs, such as monographs, book chapters, and edited collections. Recognizing the importance of diverse and open scholarly contributions, this initiative aims to facilitate open access publishing for a broader range of academic works. UCL authors are encouraged to apply for funding to cover the associated publishing costs, promoting accessibility and dissemination of scholarly knowledge.
Improving Profiles and RPS for Enhanced Accessibility: The Open Access Team is dedicated to enhancing the Profiles platform and Research Publications Service (RPS) in 2024. Plans include the development of department and group pages within these platforms, fostering a more comprehensive and accessible presentation of academic profiles, publications, and collaborative efforts. These enhancements contribute to the overall visibility of UCL research outputs and strengthen the university’s commitment to showcasing the diverse impactful work of its academic community.
Safeguarding Authors’ Rights for Open Availability: An active investigation into a UCL Rights Retention policy is underway, reflecting the Open Access Team’s commitment to safeguarding authors’ rights. This policy aims to support authors by allowing them to retain the rights to make their outputs openly available. By exploring and implementing this policy, the team seeks to align UCL with practices that prioritise authors’ control over the accessibility of their scholarly works. This initiative is an important step towards ensuring that the academic community retains agency in sharing their contributions openly.
Research Bibliometrics Team:
 New LibGuide for Metrics Tools: In 2024, the Research Bibliometrics Team is focused on supporting researchers with the knowledge and tools needed to navigate the landscape of research impact metrics. A new LibGuides is underway, focusing on key metrics tools, including InCites, Altmetric, and Overton. This comprehensive resource will serve as a guide for researchers, offering in-depth information on harnessing these tools to assess the impact and visibility of their scholarly work.
New LibGuide for Metrics Tools: In 2024, the Research Bibliometrics Team is focused on supporting researchers with the knowledge and tools needed to navigate the landscape of research impact metrics. A new LibGuides is underway, focusing on key metrics tools, including InCites, Altmetric, and Overton. This comprehensive resource will serve as a guide for researchers, offering in-depth information on harnessing these tools to assess the impact and visibility of their scholarly work.
Training for Overton: As part of the team’s commitment to enhancing research impact assessment, special attention will be given to Overton. The Research Bibliometrics Team plans to roll out further training sessions specifically designed to harness the potential of the platform as a discovery and research metrics tool. This will provide researchers with skills and understanding enabling them to use Overton effectively for evaluating the broader impact of their research in the academic landscape.
Get Involved! ![]()
As we embark on 2024, the UCL Office for Open Science and Scholarship invites you to be a part of the open science and scholarship movement. Whether you are a researcher, student, or simply curious about the future of academia, your engagement can contribute to a more transparent, collaborative, and innovative research landscape. Stay connected for updates, events, and opportunities. Follow us on X, formerly Twitter, and join our mailing list to be a part of the open science and scholarship conversation at UCL!
OOSS Annual Recap 2023
By Rafael, on 17 January 2024
As we step into a new year, let’s reflect on the collective achievements and milestones of the UCL Office for Open Science & Scholarship (OOSS) and our associated teams in 2023. This year witnessed the growth and integration of OOSS within the institutional culture of UCL, offering pivotal support to academic staff, researchers, and students. From the successful return to in-person events with our annual conference to pioneering initiatives and awards, let’s revisit the highlights that shaped our work last year!
Annual Conference & Open Access Celebrations

In April 2023, we successfully organized our annual conference, marking our first return to in-person events. Themed Open Science and the Case for Social Justice, the conference fostered important discussions on sustainability in research practices, addressing critical issues such as gender, language, authorship, and geographical disparities. Recordings of these insightful discussions are available. Notably, a workshop during the conference addressed equity in authorship, contributing to a forthcoming UCL statement on Authorship. Additionally, October saw the celebration of our Open Access week, themed Community over Commercialisation. This included a series of blog posts, activities, and discussions, emphasizing equitable access to a wide range of works.
Honouring Excellence: Inaugural Open Science and Scholarship Awards:
Another highlight was the inaugural Open Science and Scholarship Awards at UCL in collaboration with the UK Reproducibility Network. These awards aimed to recognize and celebrate the efforts of UCL students and staff who champion open science practices. Learn more about the winners and their innovative work!
Open Access: Profiles & Transformative Agreements
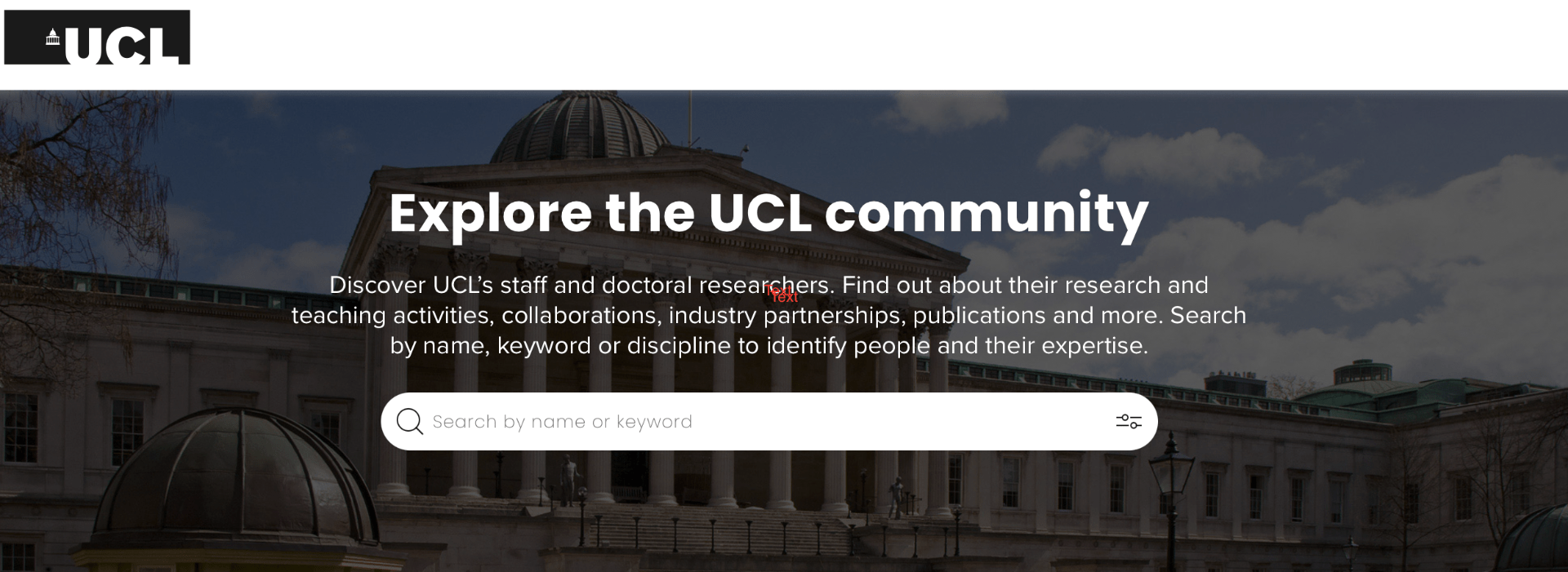
The Open Access Team played a pivotal role in ensuring the open availability of UCL academics’ research outputs throughout 2023. A major achievement was the successful introduction of the new Profiles platform, replacing the outdated IRIS. Profiles acts as UCL’s public search and discovery tool, significantly improving the visibility of academic profiles, publication lists, research and teaching activities, and collaborations with UCL colleagues. The team also facilitated the Gold open access publication of 3,383 papers in 2023, contributing to the thriving UCL Discovery with over 44 million downloads. The repository now boasts over 166,000 open access items, including 23,400 theses, with over 18,500 uploads in the preceding twelve months.
Aligned with the UKRI and Wellcome open access policies, the Open Access Team provided robust support for UCL researchers. This included facilitating compliance through publishing in fully open access journals, making use of transformative agreements with publishers encompassing over 12,000 journals, and using funders’ language to secure the right to make accepted manuscripts freely accessible upon publication under the CC BY license.
Research Data: Enhancing Support to Researchers
The Research Data team introduced a more user-friendly version of the UCL Research Data Repository, incorporating enhanced features and a comprehensive user manual. The repository saw a significant influx of 193 new items, including data sets, media items, and software applications. Engaging with researchers, the team provided substantial assistance, reviewing 32 data management plans and conducting successful training sessions for 61 researchers. Additionally, the team expanded and refined frequently asked questions (FAQs) for better user support.
Citizen Science: New website and initiatives

The Citizen Science Team expanded its reach and impact in 2023 through new Citizen Science website pages and an enhanced list of citizen science projects at UCL, fostering a greater understanding of the breadth of such initiatives across the university. The creation of a unifying definition of citizen science at UCL, accompanied by an inclusive word cloud, provided clarity on the diverse subject areas and disciplines covered by citizen science projects.
The development of the UCL Citizen Science Certificate, in collaboration with the UCL Citizen Science Academy, marked a significant milestone and underscored our commitment to fostering collaborative initiatives. A new Citizen Science community on MS Teams was launched, providing a dedicated space for discussions and updates. Get involved!
Bibliometrics: Measuring Research Impact
The Bibliometrics Team, in collaboration with the Open Access Team, played a crucial role in implementing the new Profiles system. Their research confirmed the citation advantage associated with open access practices. After a detailed analysis of UCL publications over recent years, the study demonstrated that open access materials are utilised and cited more extensively, and confirmed the place of the institution as leading organisation in making material available in open access.
Additionally, the team introduced new courses, including an introduction to altmetrics and the Overton database, aiming to assess the broader impact of published research in the wider world and cover policy documents and official documents. Another training provided an overview of understanding and demonstrating research impact, further supporting UCL’s researchers. The Bibliometrics Team’s dedication to understanding and demonstrating research impact through various courses and collaborations reinforced UCL’s position as a leader in research output accessibility.
Stay connected and Informed
![]()
The combined efforts of OOSS teams in 2023 exemplify UCL’s commitment to open and accessible research practices across diverse disciplines. As we move forward, the OOSS remains dedicated to fostering an inclusive culture of open science and scholarship, shaping a transformative academic environment at UCL.
Join us in 2024 for updates and insights, and follow us on X, formerly Twitter, to find out more about open science and scholarship at UCL!
UCL Advent Calendar of Research Support!
By Kirsty, on 1 December 2023
This year we are pleased to be able to share with you our Advent Calendar of Research Support! We will be posting every day over on our Twitter/X account but for those of you that aren’t using Twitter/X we have posted it below, and you can visit it online in your own time. We will also be updating this post throughout the month with accessible version of the content.
Day 1

The Office for Open Science and Scholarship is your one stop shop for advice and support for all things openness. Find out more on our website: https://www.ucl.ac.uk/library/open-science-research-support/ucl-office-open-science-and-scholarship #ResearchSupportAdvent
Image by Alejandro Salinas Lopez “alperucho” on UCL imagestore. A Christmas tree with white lights at night in front of columns lit with colours of the rainbow.
Day 2

Profiles is UCL’s new public search and discovery tool showcasing the UCL community. Use it to find UCL academics, their activities, collaborations, industry partnerships, publications and more. Profiles replaces the previous IRIS system: https://www.ucl.ac.uk/library/open-science-research-support/ucl-profiles #ResearchSupportAdvent
Image by Mat Wright on UCL imagestore. A girl with dark hair and wire rimmed glasses wearing a yellow jumper sits at a laptop. In the background can be seen colourful book stacks.
Day 3

If you need a more controlled way of sharing your research data, check out the UK Data Service and its granular controls for accessing data. https://ukdataservice.ac.uk/learning-hub/research-data-management/data-protection/access-control/ #ResearchSupportAdvent
Image by Alejandro Walter Salinas Lopez on UCL imagestore. Six people in office attire facing a bright yellow wall covered in postit notes
Day 4 

Our final UCL Profiles training session of the year will be held on 7 December at 12pm. Come along to find out how to update your profile and manage your professional and teaching activities in RPS. https://library-calendars.ucl.ac.uk/calendar/libraryskillsUCL?t=g&q=profiles&cid=6984&cal=6984&inc=0
If you can’t make the session, have a look at our Getting started with Profiles page: https://www.ucl.ac.uk/library/open-science-research-support/ucl-profiles #ResearchSupportAdvent
Image by Mary Hinkley on UCL imagestore. A mixed group of people around a table working at laptops.
Day 5

Are you interested in citizen science or participatory research? Ever wondered whether such an approach might work for your project? Whether you are new to citizen science or if you’ve run projects including participants before, come and join our informal UCL Citizen Science community to exchange ideas, ask for advice or share your stories! #ResearchSupportAdvent https://teams.microsoft.com/l/team/19%3aEU3Ia83bPWRqzrGpqQ1KkqlQ0AC5f4Ip8Y-zclJ-PHc1%40thread.tacv2/conversations?groupId=54f252f7-db72-40df-8faf-20e618d9a977&tenantId=1faf88fe-a998-4c5b-93c9-210a11d9a5c2
Image by Alejandro Salinas Lopez “alperucho” on UCL imagestore. A group of three women in warm clothing toasting with cups of coffee at night.
Day 6

Ever hit a paywall when trying to access scholarly publications? Get the popcorn ready, and be prepared to have your eyes opened by watching this documentary ‘Paywall: the Business of Scholarship’ at https://paywallthemovie.com/ #OpenAccess #ResearchSupportAdvent
Image by Alejandro Salinas Lopez “alperucho” on UCL imagestore. A plate of mince pies.
Day 7
Have you ever received an unsolicited email from a publisher inviting you to publish your research in their journal? Think, Check, before you submit. https://thinkchecksubmit.org/ #ThinkCheckSubmit #ResearchSupportAdvent
Image from ThinkCheckSubmit. Traffic lights containing the words Think, Check, Submit.
Day 8

If you’re sharing your data using the UCL Research Data Repository, reserve your DOI when you create the item. Then when you submit a paper for publication you can include it in the data access statement and readers will be able to find your data more easily once the data is published. https://www.ucl.ac.uk/library/open-science-research-support/research-data-management/ucl-research-data-repository #ResearchSupportAdvent
Image by UCL Media Services on UCL imagestore. A close up of a bright purple bauble on a tree with some blue lights.
Day 9

Are festive songs, recipes and party activities protected by copyright? How does this relate to your research? Answers in our latest copyright blog post: https://blogs.ucl.ac.uk/copyright/#ResearchSupportAdvent
Image by KamranAydinov on Freepik. Blue headphones surrounded by christmas decorations, stockings, candles, tree lights and pine cones.
Day 10

UCL Press has launched the first #openaccess textbook in its new programme today. Take a look here: https://www.uclpress.co.uk/products/215121. Interested in publishing an #openaccess textbook with us? Find out more: https://www.uclpress.co.uk/pages/textbooks
Image by UCL Press. Image is a red band on a white background. On the red band, white writing reads, ‘An introduction to Waste management and circular economy. Read and download free from uclpress.co.uk/waste.
Day 11

If you’ve encountered a paywall when trying to read research online, Unpaywall (https://unpaywall.org/) and the Open Access Button (https://openaccessbutton.org/) are two free browser extensions which search the internet for copies that you can access. #ResearchSupportAdvent
Image by Mary Hinkley on UCL imagestore. A close up of a Christmas tree covered in yellow lights and small silver leaves. In the background can be seen a grey building, some leafless trees and a dark grey statue of a man.
Day 12

Do you have a namesake in the world of research? To ensure that other researchers and publishers are not confusing you with someone else, sign up for an ORCID ID at https://orcid.org/ ORCID brings all your scholarly output together in one place. Read more here: https://www.ucl.ac.uk/library/open-science-research-support/open-access/orcid-ucl-researchers #ResearcherIDs #ORCID #ResearchSupportAdvent
Image by John Moloney on UCL imagestore. A group of people in business attire socialising with drinks. Picture is taken from a distance and slightly above.
Day 13

Grey literature is produced and published by non-commercial private or public entities, including pressure groups, charities and organisations. Researchers often use grey literature in their reviews to bring in other ‘voices’ into their research. We have listed some useful sources on our guide: https://library-guides.ucl.ac.uk/planning-search/grey-literature #literaturereview #greyliterature #ResearchSupportAdvent
Image by Irrum Ali on UCL imagestore. A white table covered in books and pamphlets of various sizes.
Day 14

Are you working with personal data and need more advice on the difference between anonymisation and pseudonymisation? Check out the data protection team’s guide or get in touch with them for more advice. #ResearchSupportAdvent https://www.ucl.ac.uk/data-protection/guidance-staff-students-and-researchers/practical-data-protection-guidance-notices/anonymisation-and
Image by Mary Hinkley on UCL imagestore. Two large and several small icicles against a wintery sky.
Day 15

Historical Inquiry is an important part of the research process. A place to begin this is by understanding the etymology of words. Raymond Williams began this by collating keywords of the most used terms. However, the meanings of words change over time, depending on context. The University of Pittsburgh has continued this project: https://keywords.pitt.edu/, and we have their publication in the Library. #HistoricalInquiry #ResearchSupportAdvent
Image by Mat Wright on UCL imagestore. A student with long blonde hair studies in the foreground. Behind her are rows of wooden desks and book stacks in arches sit further back.
Day 16

Did you know the Research Data Management team can review your Data Management Plan and provide feedback, including to make sure you adhere to funder guidance on data management? Get in touch to send us a plan or find out more. https://www.ucl.ac.uk/library/open-science-research-support/research-data-management #ResearchSupportAdvent
Image by Mary Hinkley on UCL imagestore. UCL front quad at twilight. In front of the portico is a Christmas tree decorated with yellow lights. To the right of the image is a leafless tree decorated with purple and pink lights which can be seen reflecting off the white building beyond.
Day 17

From 2024, UKRI funded long-form outputs must be open access within 12 months of publication under CC BY or another Creative Commons licence. UCL’s Open Access Team has info. including funding & exceptions, and offers support: https://www.ucl.ac.uk/library/open-science-research-support/open-access/research-funders/new-wellcome-and-ukri-policies/ukri #ResearchSupportAdvent
Image by James Tye on UCL imagestore. Image shows a view through a gap in books to a woman with light brown hair holding the books open and appearing to be searching the shelf.
Day 18

To coincide with the new UKRI open access policy for monographs, UCL Library Services has new funding to support all UCL REF-eligible staff who would like to make their monographs, book chapters and edited collections Gold open access. Find out about this funding and how to contact us: https://www.ucl.ac.uk/library/open-science-research-support/open-access/open-access-funding-and-agreements/open-access-funding #ResearchSupportAdvent
Image by Alejandro Salinas Lopez “alperucho” on UCL imagestore. Image shows a Christmas garland over and arch with people walking through, slightly out of focus. The garland is threaded with yellow lights and the words Happy Holiday Season are written in pink lights.
Day 19

Interested in adding grey literature into your research? Have a look at Overton – a database of 10m+ official and policy documents http://libproxy.ucl.ac.uk/login?url=https://app.overton.io/dashboard.php#ResearchSupportAdvent
Image by Tony Slade from UCL imagestore. A top-down photograph of four students working individually at wooden desks. To the right of the image are wooden bookcases full of colourful books.
Day 20

Have time in your hands this holiday? Complete our short, fun, Jedi-friendly copyright online tutorial and be copyright-savvy before the new year begins! Access at: https://www.ucl.ac.uk/library/forms/articulate/copyright-essentials/#/ #ResearchSupportAdvent
A screenshot from the UCL Copyright Essentials module. Includes information on the topics covered, some text from the module and an image of a group of stormtroopers marching in the street. Includes image by Michael Neel via Wikimedia Commons.
Day 21

Beat the cold with #openaccess reading! UCL Press have more than 300 open access books and 15 journals for you to read and download- for free! Available from: uclpress.co.uk
Image by Tony Slade on UCL imagestore. A close-up perspective shot of a bookcase. Black books with gold writing are in the foreground and red, orange and blue volumes are further back.
Day 22
Have you made your New Year resolutions yet? Start by developing your copyright knowledge. Register for one of our 2024 workshops to learn how copyright supports your research and learning. #ResearchSupportAdvent https://library-calendars.ucl.ac.uk/calendar/libraryskillsUCL/?cid=-1&t=g&d=0000-00-00&cal=-1&ct=32648&inc=0
Image by KamranAydinov on Freepik. Top view of hand holding a pen on spiral notebook with new year writing and drawings decoration accessories on black background.
Day 23

Curious to see who’s talking about your research? You can see a dashboard for all your RPS publications in the Altmetric tool – search by “verified author”. https://www.altmetric.com/explorer/#ResearchSupportAdvent
Image by Alejandro Salinas Lopez “alperucho” on UCL imagestore. An arm and hand in profile holds up a mobile phone with the camera open. The phone shows the UCL portico and Christmas tree. The background is out of focus but appears to show Christmas lights.
 Day 24
Day 24

The final day of our #ResearchSupportAdvent is upon us and we want to use it to say thank you to everyone that has supported us, come to our events, training or shared with us. Also our colleagues and friends from other institutions. All of us here in the UCL Office for Open Science & Scholarship and beyond across all of the teams represented wish you a great break and look forward to 2024!
Citizen science community at UCL – a discussion and call to contribute
By Kirsty, on 27 October 2023
Community over Commercialization was the theme for this year’s International Open Access Week. The organisers aim for this theme was to encourage a candid conversation about which approaches to openness prioritise the best interests of the public and the academic community—and which do not.
This is related to the UNESCO Recommendation on Open Science, which highlights the need to prioritize community in its calls for the prevention of “inequitable extraction of profit from publicly funded scientific activities” and support for “non-commercial publishing models and collaborative publishing models with no article processing charges.” By focusing on these areas, we can achieve the original vision outlined when open access was first defined: “an old tradition and a new technology have converged to make possible an unprecedented public good.”
-adapted from openaccessweek.org
This week, in support of this theme we have launched our Citizen Science community for anyone at UCL that wants to get involved, staff, students, anyone! It’s the culmination of a lot of work from the team in the Office for Open Science and Scholarship and I wanted to close out the week with a discussion of how we have been approaching Citizen Science at UCL and what we are going to be doing next.
One of the core values of the Office for Open Science & Scholarship, and therefore the team behind the Citizen Science community, is to make everything we do as inclusive as possible of as many of the UCL subject areas as we can.
 We use Citizen Science as a title, because it is a commonly used and recognised term, but as we want to create a broad community we have worked hard to create a unifying definition that we want to work to, and this is where this word cloud comes in! This is a work in progress where we are trying to collect as many terms for what we would consider to be a part of Citizen Science as possible and we are hoping that the new community will help us to develop this more and make it as comprehensive as possible!
We use Citizen Science as a title, because it is a commonly used and recognised term, but as we want to create a broad community we have worked hard to create a unifying definition that we want to work to, and this is where this word cloud comes in! This is a work in progress where we are trying to collect as many terms for what we would consider to be a part of Citizen Science as possible and we are hoping that the new community will help us to develop this more and make it as comprehensive as possible!
So, what else have we been doing and what are we working on?
As well as the launch of the UCL Citizen Science Academy, over the past year or so, the team has been talking to a number of colleagues that have been working on citizen science projects to get insights into the projects happening at UCL (which we have added to our website), but also the skills and support that people would recommend for new starters. This will all feed into us recommending, commissioning or developing training and support for you, our community. The aim is to keep building up our existing citizen science related community and enable new, interested parties to get involved, supported by both us and the community as a whole.
We are always asking for information about new projects, feedback on how we can make our community more inclusive and looking for new words for our word cloud so please get in touch by email or by commenting below, we love to hear from you!
Open Science & Scholarship Awards Winners!
By Kirsty, on 26 October 2023

 A huge congratulations to all of the prize winners and a huge thanks to everyone that came to our celebration yesterday! It was lovely to hear from a selection of the winning projects and celebrate together. The OOSS team and the UKRN Local leads Sandy and Jessie had a lovely time networking with everyone.
A huge congratulations to all of the prize winners and a huge thanks to everyone that came to our celebration yesterday! It was lovely to hear from a selection of the winning projects and celebrate together. The OOSS team and the UKRN Local leads Sandy and Jessie had a lovely time networking with everyone.
Just in case you weren’t able to join us to hear the prize winners talk about their projects, Sandy has written short profiles of all of the winning projects below.
Category: Academic staff
Winner: Gesche Huebner and Mike Fells, BSEER, Built Environment
Gesche and Mike were nominated for the wide range of activities that they have undertaken to promote open science principles and activities in the energy research community. Among other things, they have authored a paper on improving energy research, which includes a checklist for authors, delivered teaching sessions on open, reproducible research to their department’s PhD students as well as staff at the Centre for Research Into Energy Demand Solutions, which inspired several colleagues to implement the practices, they created guidance on different open science practices aimed at energy researchers, including professionally filmed videos, as well as developed a toolkit for improving the quality, transparency, and replicability of energy research (i.e., TReQ), which they presented at multiple conferences. Gesche and Mike also regularly publish pre-analysis plans of their own research, make data and code openly available when possible, publish preprints, and use standard reporting guidelines.
Honourable mention: Henrik Singmann, Brain Sciences
Henrik was nominated for their consistent and impactful contribution to the development of free and open-source software packages, mostly for the statistical programming language R. The most popular software tool he developed is afex, which provides a user-friendly interface for estimating one of the most commonly used statistical methods, analysis of variance (ANOVA). afex, first released in 2012 and actively maintained since, has been cited over 1800 times. afex is also integrated into other open-source software tools, such as JASP and JAMOVI, as well as teaching materials. With Quentin Gronau, Henrik also developed bridgesampling, a package for principled hypothesis testing in a Bayesian statistical framework. Since its first release in 2017, bridgesampling has already been cited over 270 times. Other examples of packages for which they are the lead developer or key contributor are acss, which calculates the algorithmic complexity for short strings, MPTinR and MPTmultiverse, as well as rtdists and (together with their PhD student Kendal Foster) fddm. Further promoting the adoption of open-source software, Henrik also provides statistics consultation sessions at his department and uses open-source software for teaching the Master’s level statistics course.
Honourable mention: Smita Salunke, School of Pharmacy
Smita is recognised for their role in the development of the The Safety and Toxicity of Excipients for Paediatrics (STEP) database, an open-access resource compiling comprehensive toxicity information of excipients. The database was established in partnership with European and the United States Paediatric Formulation Initiative. To create the database, numerous researchers shared their data. To date, STEP has circa 3000 registered users across 44 countries and 6 continents. The STEP database has also been recognised as a Research Excellence Framework (REF) 2021 impact case study. Additionally, the European Medicines Agency frequently refer to the database in their communications; the Chinese Centre for Drug Evaluation have also cited the database in their recent guidelines. Furthermore, the Bill and Melinda Gates Foundation have provided funds to support a further 10 excipients for inclusion in STEP. The development and evaluation of the STEP database have been documented in three open-access research papers. Last but not least, the database has been integrated into teaching materials, especially in paediatric pharmacy and pharmaceutical sciences.
Category: Professional Services staff
Winner: Miguel Xochicale, Engineering Sciences and Mathematical & Physical Sciences
Miguel hosted the “Open-source software for surgical technologies” workshop at the 2023 Hamlyn symposium on Medical Robotics, a half-day session that brought together experts from software engineering in medical imagining, academics specialising in surgical data science, and researchers at the forefront of surgical technology development. During the workshop, speakers discussed the utilisation of cutting-edge hardware; fast prototyping and validation of new algorithms; maintaining fragmented source code for heterogenous systems; developing high performance of medical image computing and visualisation in the operating room; and benchmarks of data quality and data privacy. Miguel subsequently convened a panel discussion, underscoring the pressing need of additional open-source guidelines and platforms that ensure that open-source software libraries are not only sustainable but also receive long-term support and are seamlessly translatable to clinic settings. Miguel made recording of the talks and presentations, along with a work-in-progress white paper that is curated by them, and links to forums for inviting others to join their community available on Github.
Honourable mention: Marcus Pedersen, PHS
The Global Business School for Health (GSBH) introduced changes to its teaching style, notably, a flipped classroom. Marcus taught academics at their department how to use several mostly freely available learning technologies, such as student-created podcasts, Mentimeter, or Microsoft Sway, to create an interactive flipped classroom. Marcus further collected feedback from students documenting their learning journey and experiences with flipped teaching to evaluate the use of the tools. Those insights have been presented in a book chapter (Betts, T. & Oprandi, P. (Eds.). (2022). 100 Ideas for Active Learning. OpenPress @ University of Sussex) and in talks for UCL MBA and Master’s students as well as at various conferences. The Association of Learning Technology also awarded Marcus the ELESIG Scholar Scheme 23/24 to continue their research.
Category: Students
Winner: Seán Kavanagh, Chemistry
Séan was nominated for his noteworthy contribution to developing user-friendly open-source software for the computational chemistry/physics research community. They have developed several codes during their PhD, such as doped, ShakeNBreak and vaspup2.0 for which they are the lead developer, as well as PyTASER and easyunfold for which they are a co-lead developer. Séan not only focuses on efficient implementation but also on user-friendliness along with comprehensive documentation and tutorials. They have produced comprehensive video walkthroughs of the codes and the associated theories, amassing over 20,000 views on YouTube and SpeakerDeck. It is important to note that software development is not the primary goal of Séan’s PhD research (which focuses on characterizing solar cell materials), and so their dedication to top-quality open-source software development is truly commendable. Additionally, Séan has consistently shared the data of all his publications and actively encourages open-access practices in his collaborations/mentorship roles, having assisted others in making their data available online and building functionality in their codes to save outputs in transferable and interoperable formats for data.
Honourable mention: Julie Fabre, Department of Neuromuscular Diseases
Julie is recognized for developing the open-source toolbox bombcell, that automatically assesses large amounts of data that are collected simultaneously from hundreds of neurons (i.e., groups of spikes). This tool considerably reduces labour per experiment and enables long-term neuron recording, which was previously intractable. As bombcell has been released under the open-source copyleft GNU General Public License 3, all future derived work will also be free and open source. Bombcell has already been used in another open-source toolbox with the same licence, UnitMatch. The toolbox’s code is extensively documented, and Julie adopted the Open Neurophysiology Environment, a standardised data format that enables quick understanding and loading of data files. In 2022, Julie presented bombcell in a free online-course. This course was attended by over 180 people, and the recorded video has since been viewed over 800 times online. Bombcell is currently regularly used in a dozen labs in Europe and the United States. It has already been used in two peer-reviewed publications, and in two manuscripts that are being submitted for publication with more studies underway.
Honourable mention: Maxime Beau, Division of Medicine
Maxime is recognized for leading the development of NeuroPyxels, the first open-source library to analyze Neuropixels data in Python. NeuroPyxels, hosted on a GitHub public repository and licensed under the GNU general public license, is actively used across several neuroscience labs in Europe and the United States (18 users have already forked the repository). Furthermore, NeuroPyxels relies on a widely accepted neural data format; this built-in compatibility with community standards ensures that users can easily borrow parts of NeuroPyxels and seamlessly integrate them with their application. NeuroPyxels has been a great teaching medium in several summer schools. Maxime has been a teaching assistant at the “Paris Spring School of Imaging and Electrophysiology” for three years, the FENS course “Interacting with Neural Circuits” at Champalimaud for two years, and the UCL Neuropixels course for three years where NeuroPyxels has been an invaluable tool to get students started with analysing neural data in Python.
Honourable mention: Yukun Zhou, Centre for Medical Image Computing
Yukun was nominated for developing open-source software for analysing images of the retina. The algorithm, termed AutoMorph, consists of an entire pipeline from image quality assessment to image segmentation to feature extraction in tabular form. A strength of AutoMorph is that it was developed using openly available data and so its underlying code can be easily reproduced and audited by other research groups.Although only published 1 year ago, AutoMorph has already been used by research groups from four continents and led to three new collaborations with Yukun’s research group at UCL. Moreover, AutoMorph has been run on the entire retinal picture dataset in the UK Biobank study with the features soon being made available for the global research community. Yukun has been complimented on the ease with which any researcher can immediately download the AutoMorph tools and deploy on their own datasets. Moreover, the availability of AutoMorph has encouraged other research groups, who are conducting similar work, to make their own proprietary systems openly available.
Category: Open resources, publishing, and textbooks
Winner: Talia Isaacs, IOE, UCL’s Faculty of Education and Society
Talia is recognized for their diverse and continuous contributions to open access publishing. As Co-Editor of the journal Language Testing, they spearheaded SAGE’s CRediT pilot scheme, requiring standardized author contribution statements; they approved and supported Special Issue Editors’ piloting of transparent review for a special issue on “Open science in Language Testing”, encouraged authors to submit pre-prints, and championed open science in Editor workshops and podcasts. Additionally, in 2016, Multilingual Matters published Talia’s edited volume as their first open access monograph. Talia also discussed benefits of open access book publication in the publisher’s blog. As a result, the publisher launched an open access funding model, matching funding for at least one open access book a year. Further showcasing their dedication to open science, Talia archived the first corpus of patient informed consent documents for clinical trials on UK Data Service and UCL’s research repository, and delivered a plenary on “reducing research waste” at the British Association for Applied Linguistics event. They have also advocated for the adoption of registered reports at various speaking events, Editorial Board presentation, in a forthcoming article, editorial, and social media campaign.
Honourable mention: Michael Heinrich and Banaz Jalil, School of Pharmacy
Banaz and Michael were nominated for co-leading the development of the ConPhyMP-Guidelines. Ethnopharmacology is a flourishing field of medical/pharmaceutical research. However, results are often non-reproducible. The ConPhyMP-Guidelines are a new tool that defines how to report the chemical characteristics of medicinal plant extracts used in clinical, pharmacological, and toxicological research. The paper in which the guidelines are presented is widely used (1613 downloads / 8,621 views since Sept 2022). An online tool, launched in August 2023 and accessible via the Society for Medicinal Plant and Natural Product Research (GA) website, facilitates the completion of the checklist. Specifically, the tool guides the researchers in selecting the most relevant checklists for conducting and reporting research accurately and completely.
Honourable mention: Talya Greene, Brain Sciences
Talya is recognized for leading the creation of a toolkit that enables traumatic stress researchers to move toward more FAIR (Findable, Accessible, Interoperable and Reusable) data practices. This project is part of the FAIR theme within the Global Collaboration on Traumatic Stress. Two main milestones have so far been achieved: 1) In collaboration with Bryce Hruska, Talya has collated existing resources that are relevant to the traumatic stress research community to learn about and improve their FAIR data practices. 2) Talya also collaborated with Nancy Kassam-Adams to conduct an international survey with traumatic stress researchers about their attitudes and practices regarding FAIR data in order to identify barriers and facilitators of data sharing and reuse. The study findings have been accepted for publication in the European Journal of Psychotraumatology. Talya has also presented the FAIR toolkit and the findings of the survey at international conferences (e.g., the International Society for Traumatic Stress Studies annual conference, the European Society for Traumatic Stress Studies Biennial Conference).
Open Access Week: A year in review
By Kirsty, on 25 October 2023
![]() It has become somewhat of a tradition now for there to be a post during Open Access Week that reviews the previous year. While the middle of October may seem like a strange time to take stock, it is after all the anniversary of the Launch of the Office for Open Science & Scholarship and we like to stop and celebrate another year.
It has become somewhat of a tradition now for there to be a post during Open Access Week that reviews the previous year. While the middle of October may seem like a strange time to take stock, it is after all the anniversary of the Launch of the Office for Open Science & Scholarship and we like to stop and celebrate another year.
This year we celebrated another successful conference and our first back in person for us! We also had another first with a workshop taking place simultaneously online and in person on the topic of equity in authorship. This work has been fed into a UCL statement on Authorship that will be released in the coming months.
We also released a brand new page bringing together all of the training and support information across all the Open Science affiliated teams to make it easier to navigate and get your questions answered.
In the past year all of the teams that form part of the office have worked hard on developing new services and making improvements to existing ones.

The Open Access team have been working hard updating RPS and the new Profiles tool to replace IRIS. They also support both Gold and Green Open Access Activity across the university.
Over 18,500 items have been uploaded to UCL Discovery in the last 12 months, bringing the total to over 166,000! Of these, there are over 23,000 theses to be explored. They have also made 3,383 papers Gold OA, 2,700 of which were using our transformative agreements with publishers.
The Research Data Management team have been working hard behind the scenes doing an overhaul of their support materials, testing new materials for training and supporting the ever-growing Research Data Repository.
In the past 12 months we have had over 1000 new datasets from 226 users. Quite notably, we have had over 200,000 downloads which just goes to show the value of sharing your data as well as your other research outputs!
The Citizen Science support service has moved on in leaps and bounds since this time last year, creating content, liaising with colleagues across the university, collaborating to launch the UCL Citizen Science Academy and this week we were able to launch the brand new Citizen Science online community.
Hopefully that gives you a taste of what we have been up to and the numbers of the last year, scroll back through the blog for more information and to get an idea of the detail of what we have been up to. It’s been a great year and here’s to the next!
Happy Open Access Week!
Launching our new UCL Citizen Science Community on MS Teams!
By Kirsty, on 24 October 2023
Are you interested in citizen science?
Would you like to connect with others to share your stories about citizen science?
Are you wondering whether a citizen science approach might work for your project?
Would you like to collaborate with colleagues across UCL and exchange ideas or work together on participatory projects under a joint mission?
Do you want to hear about citizen science as an approach or would you just like to expand your network?
If so, please join our informal UCL citizen science community and get involved! Whether you are new to citizen science or whether you have run projects before, this is your community. We are bringing everyone together to share their knowledge, discuss good practices and talk about their experiences of citizen science. The community is strictly for UCL members only but is open to all staff and students at all levels.
You might call it participatory research, community action, crowdsourcing, public engagement, or something else. UCL supports a broad approach to “citizen science”, recognising that there are different applications and functions of this approach in research, whether they are community-driven research projects or global investigations.
Through this community, we would really like to hear your feedback on what you would like to see from a potential citizen science support service at UCL including any ideas you might have for events, training, resources or anything else. Join here or search “UCL Citizen Science Community” on Teams.
We also have brand new and improved Citizen Science web pages on the UCL’s Office for Open Science and Scholarship website which includes an introduction to citizen science at UCL including definitions, history, types and levels, and information about the UCL Citizen Science Certificate, you can browse through the various types of citizen science projects at UCL and learn about what your colleagues are doing in this exciting area!
On our new citizen science support and training page, you will find links to relevant training courses currently delivered by different UCL teams both online and in person, a variety of useful resources about citizen science, links to interesting blogs/news and citizen science platforms and projects outside UCL. We will be improving and expanding this content within the coming months.
If you have any questions, would like further information or would like to tell us what you need, please contact us!
How Creative Commons licences support open scholarship
By Kirsty, on 23 October 2023
Happy Open Access Week 2023!
This year’s theme is ‘community over commercialisation’. It is about adopting research and education practices that place priority on the interests of the public. In the context of scholarly communications, it is about making access to scholarly knowledge open and accessible to diverse communities, in transparent and sustainable ways.
For this to be achieved, the outcomes of academic research and education – research data, preprints, published articles, monographs, educational resources – must be open to access but also open to reuse: free access to an article, an online tutorial or a dataset has great benefits, but the potential for users of these materials to share them with others, adapt, add to and improve upon them is what makes innovation and creativity possible.
Creative Commons (CC licences) support open and reusable research by offering a standardised way in which authors can grant others certain permissions to reuse their works. In this post we highlight some key points about CC licences and discuss how they benefit both creators and users of copyright-protected materials.
What is Creative Commons?
Creative Commons (CC) is “an international non-profit organisation dedicated to helping build and sustain a thriving commons of shared knowledge and culture”. The organisation is active in supporting, educating and advocating for a more open culture; but it is most known for its licences.
How do Creative Commons licences work?
If you are the author of pretty much any creative work – a journal article, an image, a music composition, a website, a book – making your work available under a CC licence helps you:
- As the copyright owner of the work, give ‘blanket’ permission to others to copy and share your work, while requiring that they attribute you as the author.
- Decide what further uses you give blanket permission for. Do you allow others to make adaptations(e.g. to translate your book, adapt a teaching resource for a new audience, or change your artwork)? Do you allow others to reuse for a commercial purpose?
- Decide if you would like to ensure that future adaptations of your work (if you are allowing them) are also made available under the same licence, keeping them as ‘open’ as yours.

Image attribution: Barbara Klute und Jöran Muuß-Merholz für wb-web unter CC BY-SA 3.0. The English version is a translation and enhancement by Jöran Muuß-Merholz under the same license., CC BY-SA 3.0, via Wikimedia Commons
The combination of these criteria: attribution (a requirement for all licences), allowing/not allowing derivatives, allowing/not allowing commercial reuse, and requiring/not requiring sharing under the same licence (‘share-alike) creates a set of six licences creators can choose from.
How do Creative Commons licences support open scholarship and the needs of different communities?
There are numerous examples of how CC licences help free up research and education. CC licences applied to open access articles, conference proceedings, monographs and other scholarly works make it possible for readers of these works around the world – who may include academic researchers, lecturers, students but also health practitioners, innovators, artists and the general public – to benefit from these works and potentially create something new and innovative as a result. CC licences applied to research data enables data to be shared and reused across different organisations and countries. CC licences applied to preprints, study preregistrations and theses ensure openness in research that is not yet formally published. In the same way, particularly through allowing adaptations, CC licences support the development and success of Open Educational Resources (OERs).
Beyond traditional scholarship, CC licences help open up cultural collections and offer opportunities for publishers and the creative industries to adopt new business models that serve their audiences better.
How can I learn more about Creative Commons?

Image attribution: adapted from Martin Missfeldt https://www.bildersuche.org/ CC BY-SA
If you have made it so far in this post, you may have further questions including how to apply a CC licence, how to discover and reuse CC materials, how CC licences work alongside copyright and how they can support commercially sensitive works. Here are a few things you can do:
- Drop-in any time between 12 pm and 2 pm on Teams on Tuesday 24 October, to hear more, ask questions and tell us about your experiences with CC licences. You can join for just a few minutes to ask a question or stay for longer to become a CC expert. Register for the CC licences drop-in session.
- Take our 5-question fun personality quiz to discover which licence you are. You may not learn anything new about yourself, but you will hopefully get even more familiar with how the range of CC licences can be applied in different situations. Your responses will be anonymous.
- Discover more CC activities and news on the Creative Commons blog.
Open Access Week activities
By Kirsty, on 13 October 2023
Open Access Week is almost upon us!
Keep your eyes open for a series of blog posts on Creative Commons, citizen science, the recent activities of UCL Press and an exciting review of a year in open access.
 This year’s theme is Community over Commercialisation. Creative Commons licences sit at the heart of this discussion. To this end, we invite you to a drop-in session on Tuesday the 24th of October to address questions around creating and using Creative Commons materials. The session is on Teams and you can join at any time. Bring along your questions or just join to discuss how CC supports equitable access to a wide range of works, from scholarly publications to open and FAIR data to images and music.
This year’s theme is Community over Commercialisation. Creative Commons licences sit at the heart of this discussion. To this end, we invite you to a drop-in session on Tuesday the 24th of October to address questions around creating and using Creative Commons materials. The session is on Teams and you can join at any time. Bring along your questions or just join to discuss how CC supports equitable access to a wide range of works, from scholarly publications to open and FAIR data to images and music.
We have already announced our wonderful winners of the Open Science and Scholarship awards. UCL colleagues can also join us on Wednesday to celebrate and network with the winners, tickets are still available!
We will be posting and tweeting regularly throughout the week about the services and support available to researchers and I hope that we can get some good discussions going!
See you there!
