 Close
Close

What’s the evidence?
By rmhipmt, on 25 June 2010
Two things happened yesterday that made me think about how we assess the evidence for and against a hypothesis. The first was a radio debate in which a politician – known to his detractors as the Right Hon. member for Holland & Barrett – was arguing with a scientist about what we could infer from three selected studies of homeopathy. The second was a session with MSc students talking about how to evaluate and present the conclusions in their dissertations. The specific difficulty we were considering was how to be honest in presenting the limitations of one’s work without undermining it.
One way to look at the published literature relating to a particular question is funnel plot. You identify all the known studies addressing the question and then create a scatter plot with a measure of study quality (e.g. sample size) on the y axis and a measure of the effect (e.g. patients improved) on the x axis. In an ideal world the identified studies would be scattered around the the true effect, with the better studies being more tightly clustered and the less accurate ones being more widely spread. The shape should resemble an upside-down funnel that straddles a line marking the true effect. What you actually see is generally more like this:
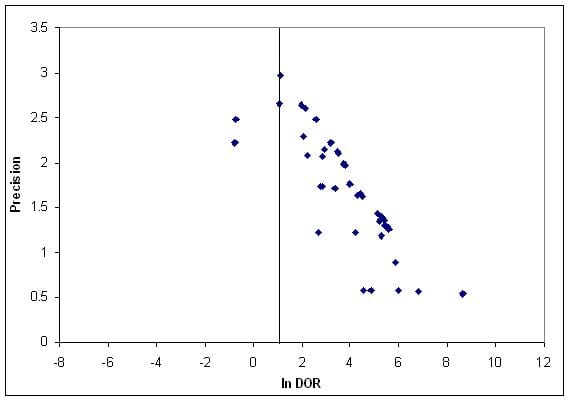
Funnel plot of studies of computer aided detection in mammography, thanks to Leila Eadie
There is an obvious asymmetry and it’s easy to explain. The bottom left corner is missing: small studies that show little or no effect aren’t there. Either researchers don’t bother to write them up, peer reviewers reject them or editors spike them. And you can see why: it’s a small study, and nothing happened.
But there’s a problem. The big studies, the ones that command attention even when the results are disappointing, are hard to fund and hard to complete. The result is that for some hypotheses (say getting children to wave their legs in the air before class makes them clever) we probably only ever see the studies that would be at the bottom right of the ideal plot. How can we judge the true effect?
My conclusion is that there is strong responsibility on those of us who work in fields where there are relatively few large, well-resourced robust studies to be self-critical and to look at how we examine and use evidence to support the claims we make.